为什么要用HDFS,优点和缺点是什么?
首先说一下优点:
- 可以存超大文件
- 一次写入,多次读取
- 可运行在廉价集群上,一个节点坏了还能继续运行
然后是缺点:
- 不能低延迟时间的访问:HDFS是为了高吞吐优化的,如果要低延迟可以用HBase
- 不能有大量小文件:因为namenode把文件的元数据都存在内存,大量小文件会给namenode巨大压力
- 不能多用户进行写入操作,也不能任意位置修改文件
下面开始介绍HDFS
首先要了解HDFS数据块
- 磁盘有一个Block的概念,它是磁盘读写数据的最小单位,HDFS也有Block
- HDFS可以把一个大文件按照Block的大小进行拆解,存到不同的Block上,并且所有的Block不需要在同一个节点上
- 每个Block都可以单独做备份,防止节点坏掉数据丢失
然后要了解的是Namenode和Datanode
- Namenode是管理员:管理整个文件系统的数结构和元数据,包括HDFS系统快照和日志文件,并且他知道一个文件的全部Block在哪些Datanode上
- Datanode是工作者:他就负责存储和读取这些Block,还会定期向Namenode汇报他存储的Block的列表
最后是最重要的HDFS是怎么读写的?
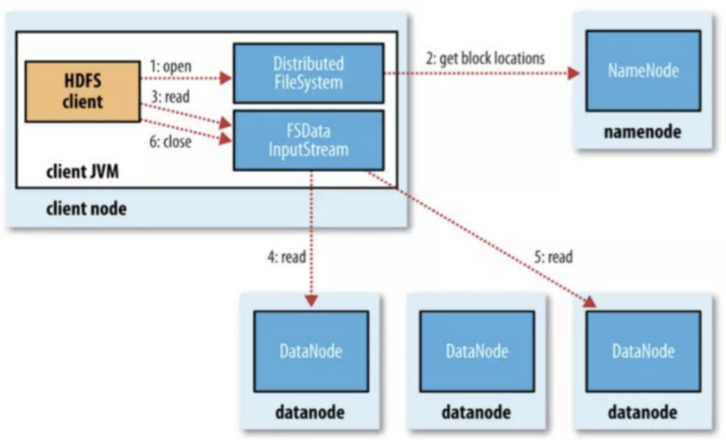
首先是从读取数据:
- 首先client调用DistributedFS的一个实例的open()方法
- 然后DistributedFS会调用Namenode获取文件起始块的Datanode地址
- 这个时候DistributedFS会返回一个FSDataInputStream的数据流对象
- 然后可以反复调用这个对象的read()方法,数据从Datanode传输到客户端
- 读取过程中FSDataInputStream会封装一个DFSInputStream去问Namenode下一批数据块的Datanode地址
- 读完就close()
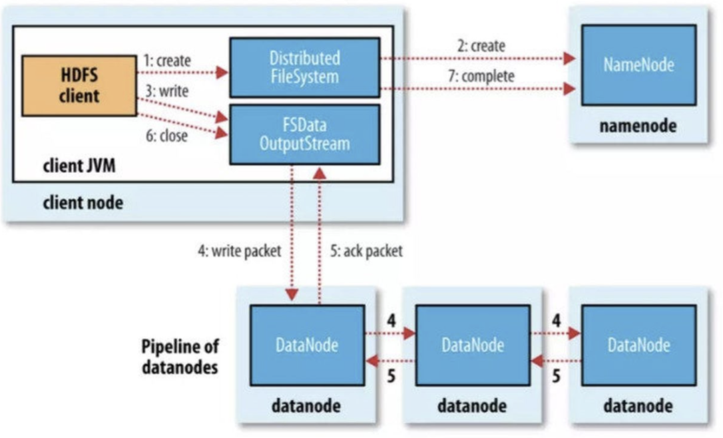
然后是写入数据:
- 首先client调用DistributedFS实例的create()方法来新建文件
- 然后DistributedFS就会请求Namenode创建一个文件,namenode经过一系列检查后创建一条新建记录
- 然后DistributedFS向client返回一个FSDataOutputStream对象,这样就可以开始写数据了
- 写的过程中,FSDataOutputStream会封装一个DFSOutputStream对象,这个对象会把数据拆成一个个数据包,放到”数据包队列中”
- 然后DataStreamer会让一组Datanode分配新的Block来存储这些数据,然后把数据一个个发送到这些Datanode组成的管道
- 管道中所有Datanode都收到后会发送ack应答包回来,然后只有收到ack后数据包才会从队列中删除
- 写完后close()