首先YARN是什么?
在Hadoop1.0的时候,MapReduce的JobTracker负责了太多工作,接收任务是它,资源调度是它,监控TaskTracker还是它,显然不合理
所以在hadoop2.0的时候就把资源调度的任务分离出来,让YARN接手这个任务
所以YARN就是一个资源调度框架
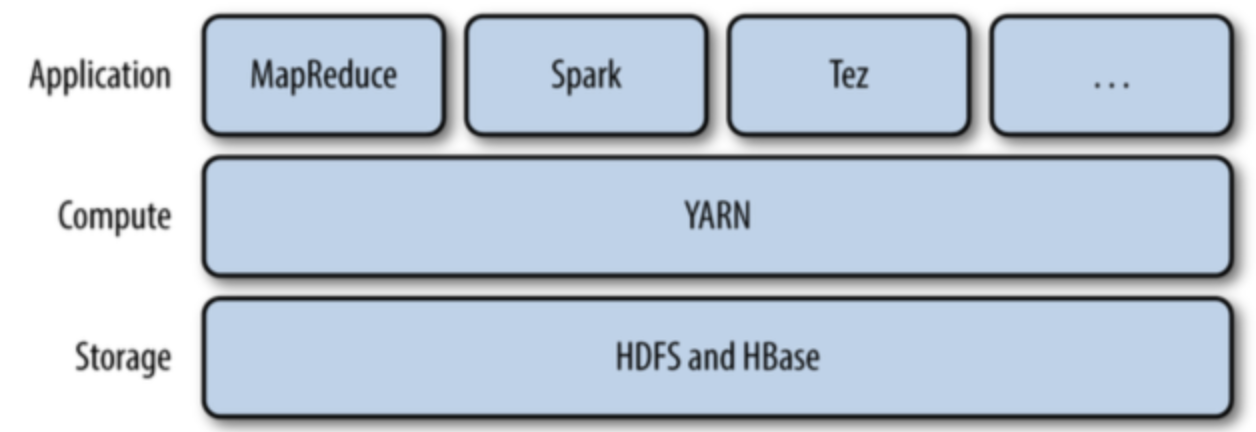
YARN是怎么运行的呢?
在介绍YARN运行机制之前,首先要了解几个概念:
- Container:容器,是YARN对资源进行的一层抽象,如把CPU核数、内存等计算资源封装成一个个Container
- ResourceManager:负责资源调度,整个系统只有一个ResourceManager,例如调度刚刚学的Container
- NodeManager:是ResourceManager在每台机器上的代理,负责管理和监控Container
- ApplicationMaster:负责协调运行MapReduce作业,把一个作业拆成多个 task,并向 ResourceManager 申请容器
我们来看一下提交一个作业到YARN中的流程:

我们来具体说说每一步的过程:
- 首先 Client 向 Yarn 提交 Application,假设是一个 MapReduce 作业
- 然后 ResourceManager 向 NodeManager 申请第一个容器,在这个容器里运行对应的 ApplicationMaster 进程
- 然后 ApplicationMaster 把这个作业拆成多个 task ,这些 task 可以在一个或多个容器里运行
- 然后向 ResourceManager 申请要运行程序的容器,并定时发送心跳
- 申请到容器后,ApplicationMaster 把作业发到对应容器的多个 NodeManager 的容器里去运行,这里运行的可能是 Map 任务,也可能是 Reduce 任务
- 运行任务的时候会向 ApplicationMaster 发送心跳,汇报情况
- 程序运行完成后, ApplicationMaster 再向 ResourceManager 注销并释放容器资源

