Map和Reduce分别是什么?
- MapReduce任务过程分为两个阶段,分别是Map和Reduce,即程序员实现Mapper和Reducer两个接口
- 什么是Map,就是拆,把拼好的乐高汽车玩具拆成一块块积木,每个积木都是一个
<Key,Value>键值对- 在Map和Reduce中间有时候需要shuffle,就是把Map拆出来的<Key,Value>打乱,并按照key排序和分组,组成
<Key,List<Value>>- 什么是Reduce,就是组合,用积木组合成变形金刚,对Value进行一些操作,如SUM、MAX等,得到一个
<Key,Value>
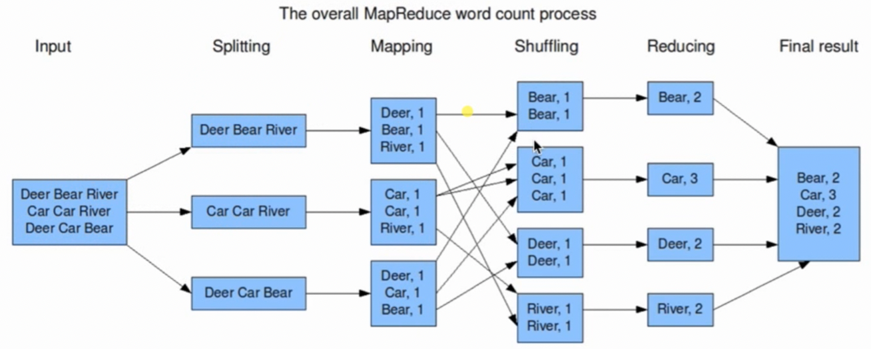
MapReduce的数据流是什么样的?
- 首先对于一个MapReduce作业(job),Hadoop会分为Map任务和Reduce任务
- Hadoop会把输入数据分成多个大小相同的数据块,即
数据分片,每个分片对应一个Map任务,并且由这个Map任务来运行自定义的Map函数
需要注意的是:
- 在创建Map任务时,一般会在对应分片的机器上运行,否则再考虑同一个机架上的其他机器,甚至是其他机架
- Map任务会输出在
本地磁盘上,而不是HDFS。因为数据是暂时的,作业完成就可以删除 - 可以使用Combiner函数
优化MapReduce,例如求MAX,可以在每个分片Map任务后先求MAX,然后再传给Reduce,这样就减少了Map和Reduce之间的传输数据量,提高性能

