本笔记是对《贝叶斯网络结构学习算法研究》论文进行学习时所写
上篇文章我们了解了什么是HDFS、MapReduce和Spark
该论文还需要学习的内容如下:(本文只解决第一个问题)
- 如何用分布式实现GA算法?
- 如何用Spark实现基于GA的BN结构学习算法?
- 如何基于Spark构造超结构?
- 如何基于Spark实现评分计算?
- 如何基于Spark实现种群演化?
第1个问题,如何用分布式实现GA算法?
使用分布式实现GA算法的方法有三类,主从模型、岛屿模型和网格模型,该论文使用的是主从模型,故仅对此进行介绍
- 主从模型:用一个主节点来管理所有的子种群,并且个体放在从节点上,然后分别在从节点上计算个体的适应度
流程呢就是:基于主从模型,用MapReduce跑GA的评价算子(适应度函数)
- 可以用多个Mapper并行计算每个染色体的适应度,然后用单个Reducer收集结果和完成遗传操作(选择、交叉、变异),这样繁殖一代就是一轮MapReduce
第2个问题,如何用Spark实现基于GA的BN结构学习算法?
首先再次说一下如何基于GA实现BN结构学习算法?
- 首先要构造一个超结构
- 初始化GA种群
- 然后对这一代进行适应度计算,即BIC评分
- 然后开始交叉变异,繁衍下一代
- 重复上述操作,直到满足条件
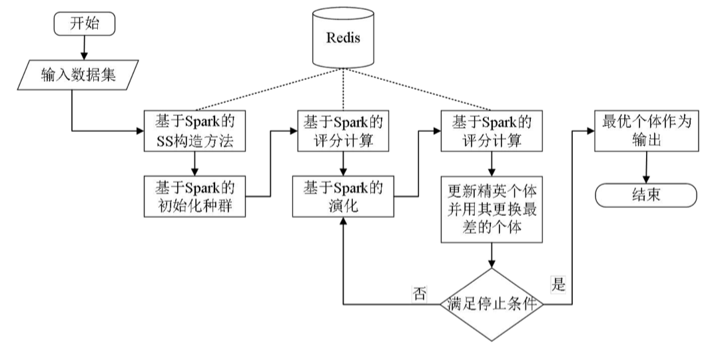
那么怎么用Spark实现基于GA的BN结构学习算法呢?
- 首先用Spark并行计算互信息并构建超结构,初始化种群
- 然后用Spark并行计算个体的BIC评分
- 然后用Spark并行演化出下一代个体
- 重复上述操作,直到满足条件,最后选择BIC评分最高的个体作为最终BN结构
故下面将详细介绍上述三个操作的步骤
基于Spark实现的第1个操作,如何构造超结构?
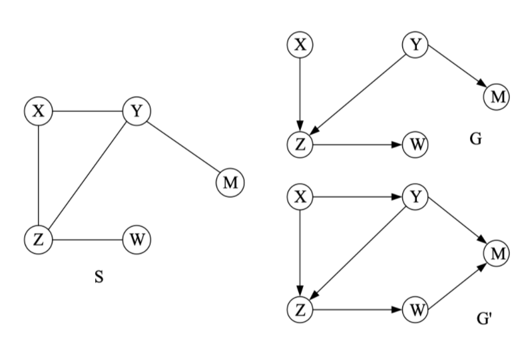
首先搞清楚啥叫超结构?
- 如下图,G的每条边都在S上,所以S是G的超结构,这种就叫超结构。但是不是G’的超结构因为W->M不在S上
如何构造超结构?
- 首先从HDFS中获取数据集D
- 计算互信息所需要的”情况变量集”,这个情况变量集就是放数据集中所有的情况,然后标上序号,给Mmi使用

- 然后广播这个”情况变量集”
- 如下图所示,就是对数据集统计各情况出现的次数,得到键值对存入Redis。用这些次数构建一个辅助矩阵Mmi,我猜这个矩阵应该是一个一维数组,放了情况变量集的每种情况在数据集中出现的次数,这个数组可在BIC计算时复用
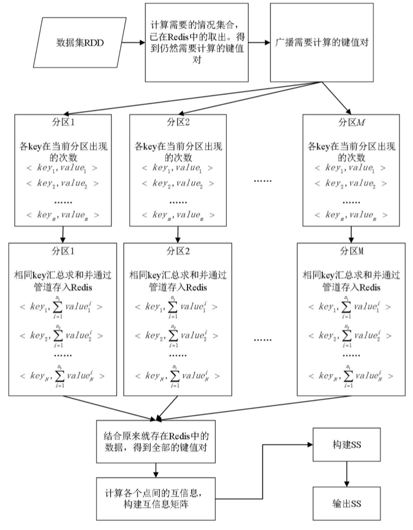
- 然后通过辅助矩阵Mmi并通过互信息计算公式如下图计算两两节点的互信息,构造互信息矩阵
- 互信息值记为MI,最后步骤如下图所示


基于Spark实现的第2个操作,如何初始化GA种群?
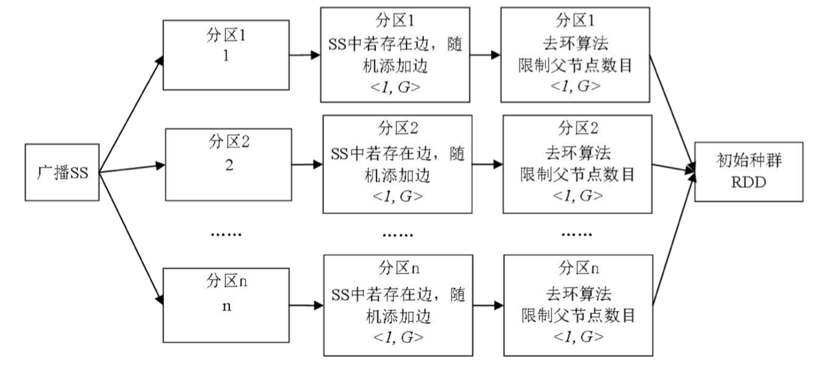
在我们构建完超结构后,还需要初始化种群RDD
- 首先要把超结构广播到每个分区
- 然后在每个分区,用Map方法基于超结构进行随机生成个体,例如超结构中每个边的两点AB,随机生成A->B、B->A和无连接,这样得到的个体组成BN结构种群RDD
- 但是BN结构不能有环,使用GR去环算法,得到合法的种群RDD
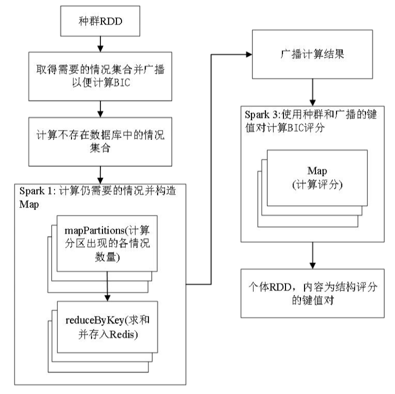
基于Spark实现的第3个操作,如何实现评分计算?
- 首先对种群RDD中每个BN结构BIC计算时需要的情况进行计算,然后把每个分区计算的这个集合合并
- 然后把redis中已经算过的去掉,剩下的情况集合记为Sneeds广播
- 还是用Map方法对RDD中的每个分区计算Sneeds中情况出现的次数,构造情况出现次数键值对
- Reduce方法在每个分区求和,并计入Redis
- 还是用Map对分区内每个个体计算BIC评分,还是构造每个个体的评分键值对
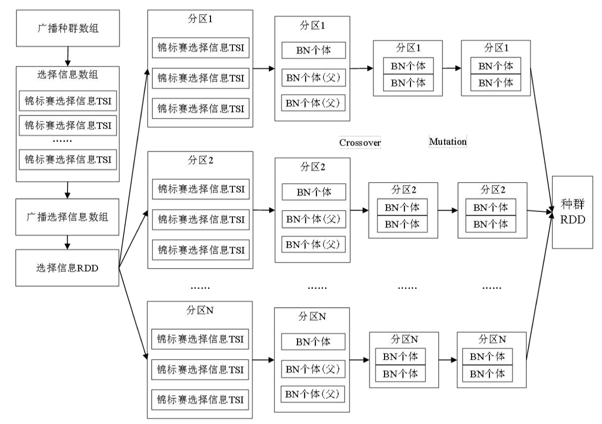
基于Spark实现的第4个操作,如何并行演化?
- 首先要进行选择和交叉:
- 首先广播种群数组,记种群数组长度为Nc
- 然后构建长度为分区数N的锦标赛数组,其中每个元素是长度为T的[0,Nc)的随机数的数组TSI,广播这个数组
- 然后在每个分区中再随机添加两个TSI数组,这样每个分区都有三个TSI数组
- 每个分区用Map方法,对第一个TSI数组直接取得BN个体,记为G0;后两个TSI分别得到两个<BN,BIC评分>的键值对,进行均匀交叉,并对交叉后的BN个体通过去环算法合法化,记为G1
- 然后对交叉后的BN个体G1进行单点突变,并通过去环算法合法化,记为G2
- 最后把G0和G2作为数组输出,作为下一代种群RDD