本笔记是对《贝叶斯网络结构学习算法研究》论文进行学习时所写
上篇文章我们了解了什么是BN结构学习算法以及GA算法
该论文还需要学习的内容如下:(本文只解决第一个问题)
- 什么是Spark分布式计算平台?
- 如何用分布式实现GA算法?
- 如何并行化构造超结构?
- 如何基于Spark实现GA算法?
- 如何基于Spark实现评分计算?
在学习Spark之前,先了解以下分布式计算框架
首先是Hadoop平台,即一个面向大数据的分布式基础架构
其中HDFS是分布式文件系统,把大数据进行切分然后存储到HDFS的若干节点上
- HDFS有两种节点,NameNode(NN)和DataNode(DN)。运行时一般是一个NN多个DN
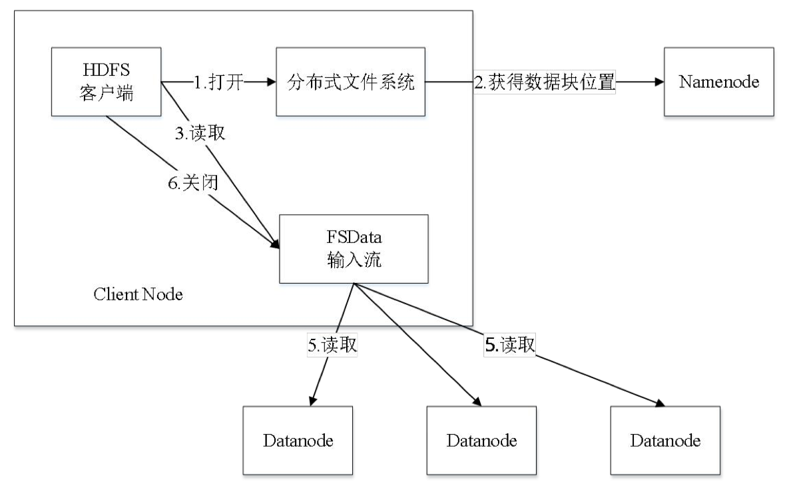
- 读取步骤:首先HDFS客户端通过分布式文件系统向NN请求下载文件,NN查询元数据找到该文件所在的多个DN地址,客户端依次通过FSData输入流向DN地址请求并读取数据,直到完成读取
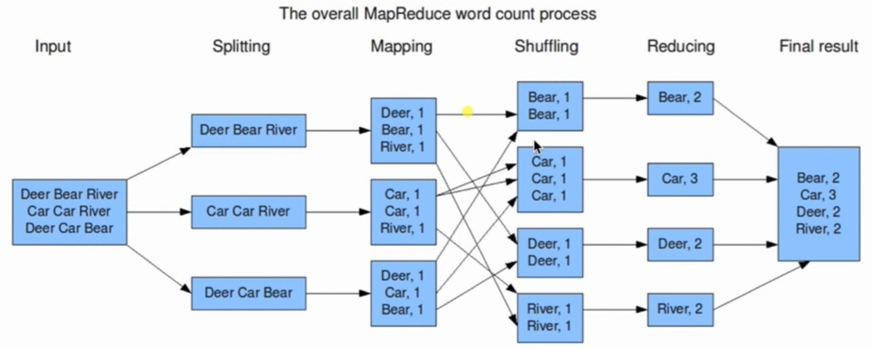
然后介绍一下MapReduce(MR),MR是一个并行处理数据的编程模型,用来对大数据进行计算
- MR流程分为两个阶段,Map阶段和Reduce阶段,分别由Mapper和Reducer两个接口实现
- 什么是Map,就是拆,把拼好的乐高汽车玩具拆成一块块积木
- 什么是Reduce,就是组合,用积木组合成变形金刚
- 那么怎么实现MR呢?如下图所示,一般先把大数据分成一”片”一”片”,然后每一”片”都由一个Map去拆,拆好了以后再shuffle归类成一组一组的,然后Reduce把每一组进行组合
终于可以开始学习Spark了
Spark是基于MR的一个处理大数据的计算框架,比MR速度更快
其中SparkSQL用来处理数据,SparkML用来做机器学习,SparkStreaming用来做流计算
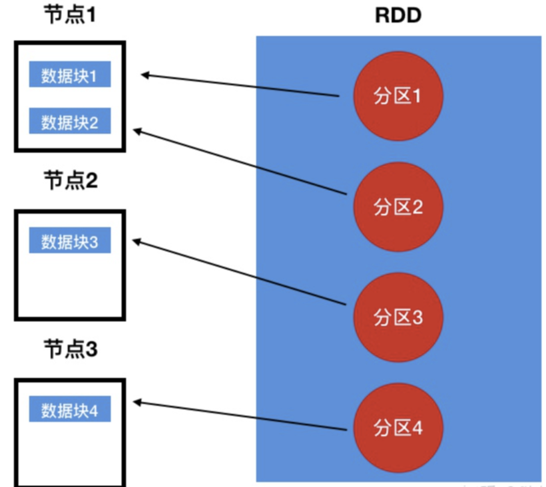
Spark底层是用的RDD来处理数据的,RDD是什么?
- RDD其实是一个抽象概念,弹性分布式数据集。
- RDD这个数据集是放在内存里的,并且RDD可以分区,每个分区放在集群的不同节点上,从而可以并行操作
- 通俗来说,RDD的表现形式类似数据库的视图,是抽象的,如下图所示