本笔记是对《贝叶斯网络结构学习算法研究》论文进行学习时所写
首先通过摘要
可以了解到该论文研究的方向,即在大数据情况下基于遗传算法的贝叶斯网络结构算法执行效率问题
作者将混合方式的 BN 结构学习算法与 Spark 分布式计算平台结合
在构建超结构、评分计算和 GA 的进化操作三个流程上进行了并行化工作
同时引入Redis对中间数据进行存储以便在评分计算过程中高效复用数据
故对该论文需要学习的内容如下:(本文只解决前3个问题)
- 什么是BN结构学习算法?
- 什么是GA算法?
- 怎么使用GA算法来得到BN结构?
- 什么是Spark分布式计算平台?
- 如何并行化构造超结构?
- 如何基于Spark实现GA算法?
- 如何基于Spark实现评分计算?
第1个问题,什么是BN结构学习算法?
首先回答什么是BN结构?
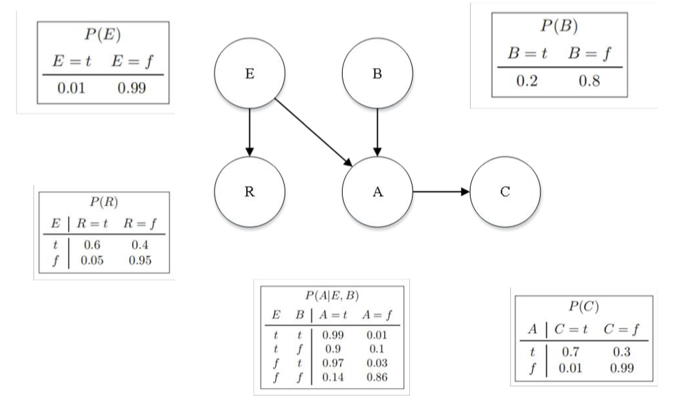
- BN,即贝叶斯网络,是一种反应世界上一些事物的可能的情况的发生概率的模型,可模拟任何系统
- BN结构,是由有向无环图(DAG)和一组条件概率表组成
- 其中DAG每个节点表示随机变量,有向边表示一个变量对另一个变量的影响
- 条件概率表表示每个节点x在其父节点的所有可能的联合赋值条件下的x的概率分布,例如下图节点A在父节点E、B所有可能的联合赋值条件下的概率
现在可以回答BN结构学习算法了
- 我们使用BN的目的就是为了得到那一组条件概率表,那么首先得构建一个BN网络,即那个有向无环图
- 那么怎么构造呢,很复杂的关系没办法手动构造吧,那么就是这里讨论的BN结构学习算法了
当然啦,那个概率表也是要训练的才行的,不过这里讨论的是BN结构哈
- 该论文指出BN结构学习算法主要是三种,基于评分、基于约束、约束和评分混合
首先是基于评分,第一步定义评分函数、第二步采用搜索策略
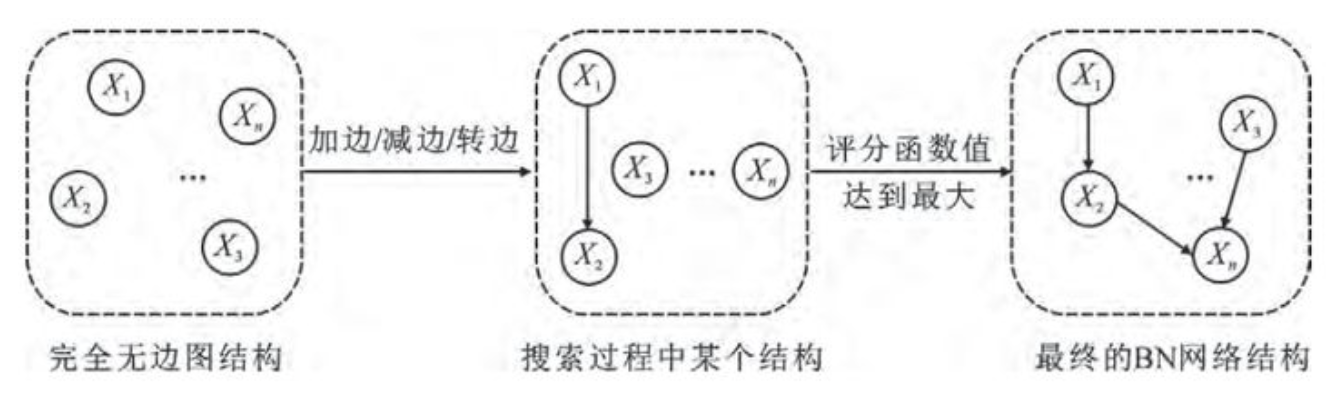
- 该论文采用BIC评分函数,由BN结构的对数似然度和惩罚项函数组成。前者表示数据集和BN结构的拟合程度,后者防止结构模型过于复杂、参数过多,导致过拟合问题。BIC评分计算方法见如下图,这里仅作了解

- 搜索策略就是在搜索空间中找得分最高的BN结构,也就是对数据集拟合程度最高的BN结构,该论文用的GA算法,下面就会介绍
然后是基于约束,就是计算各节点间条件是否独立,并通过构造条件独立性集合来建立BN
- 比如对于一个节点x,我们要求他的B(x),即与他有条件联系的节点集合,即互信息。再用CI测试给边定向
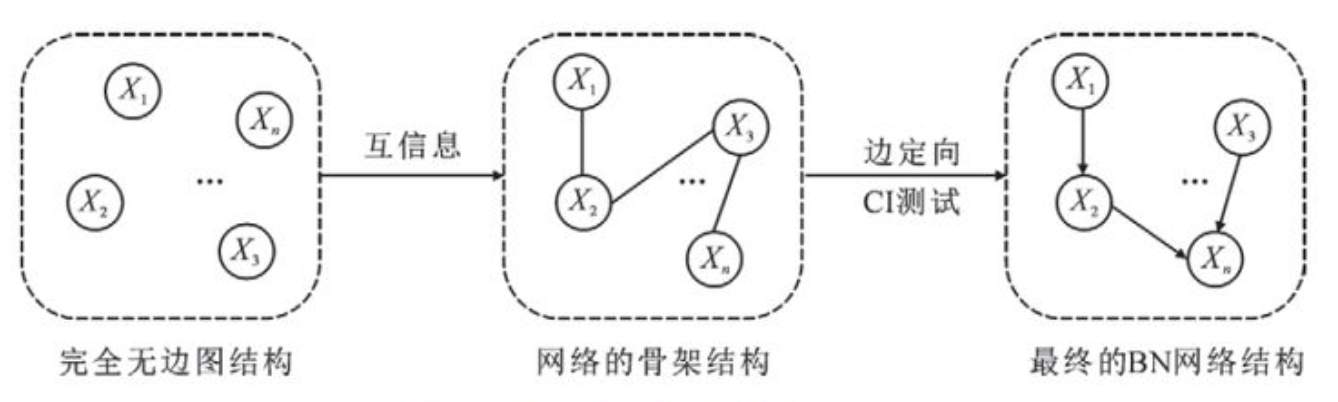
最后是混合算法,即首先通过基于约束的方法构造无向图减少冗余搜索空间,然后通过基于评分搜索的方法得到评分最高的BN结构
第2个问题,什么是GA算法?
GA算法,即遗传算法。有以下几个概念:
- 染色体:数学问题的每一个可行解就是一条染色体
- 基因:染色体上的元素就是基因,比如染色体[1,2,3],那么每个数都是一个基因
- 适应度函数:每次繁衍后,适应度函数给生成的下一代所有的染色体打分,分数高的更有可能保留下去,分数低的淘汰
- 交叉:下一代染色体由父母两条染色体交叉形成,如下图所示。爸爸妈妈染色体的选择一般用轮盘赌算法,适应度高的更容易被选中
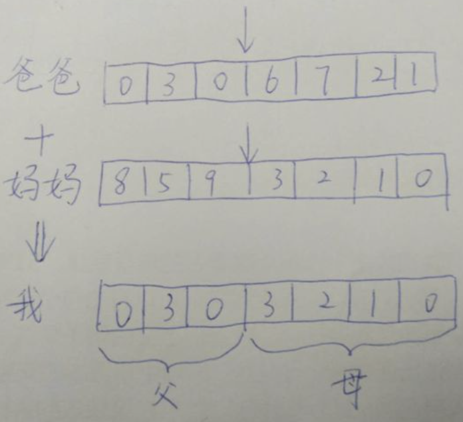
- 变异:交叉每次选择都是在原有数据集上选择,容易达到局部最优,但不能全局最优。变异就是在交叉后,对染色体上的若干个基因随机修改,从而达到全局最优
GA算法执行流程?
首先设置种群大小,突变概率,交叉概率等参数,然后随机初始化个体构成初始种群。每一次通过适应度函数打分,然后交叉、变异得到下一代,不断迭代
第3个问题,怎么使用GA算法得到BN结构?
将GA算法应用到BN结构学习中
- 首先选择操作:将适应度函数应用到对个体的BN结构评分,评分越高说明BN结构适应度越高
- 然后交叉操作:父母BN结构进行交叉,产生下一代BN结构
- 还有变异操作:对BN结构的若干基因进行随机变异,避免达到局部最优却无法全局最优解的情况

