常用Transformations()操作
| rdd2 = rdd1.map(func) | 对rdd1中的每个元素进行处理和输出 | P51 |
|---|---|---|
| rdd2 = rdd1.mapValues(func) | 对rdd1中的每个<K,V>,对每个V进行处理和输出 | P51 |
| rdd2 = rdd1.filter(func) | 对rdd1中的每个元素过滤出符合func的元素组成新RDD | P52 |
| rdd2 = rdd1.filterByRange(a,b) | 对rdd1中的每个元素过滤出在(a,b)范围内的元素组成新RDD | P52 |
| rdd2 = rdd1.flatMap(func) | 对rdd1中的每个元素进行处理,再平坦后组成新RDD | P53 |
| rdd2 = rdd1.flatMapValues(func) | 对rdd1中的每个<K,V>,对V进行flatMap操作形成新RDD | P53 |
| rdd2 = rdd1.sample(true,0.5) | 对rdd1中的数据进行抽样,参数:(放回抽样,抽样比例,随机数种子) | P54-55 |
| rdd2 = rdd1.sampleByKey(true,map) | 对rdd1中的数据根据map进行抽样,map为key和抽样比例的映射 | P54-55 |
| rdd2 = rdd1.mapPartitions(func) | 对rdd1中的每个分区进行一次性处理,处理完毕后输出 | P55 |
| rdd2 = rdd1.mapPartitionsWithIndex(func) | 同mapPartitions,区别在新RDD带有索引,表示对应哪个分区 | P56 |
| rdd2 = rdd1.partitionBy(Partitioner) |
对rdd1重新设置分区数,可设置hash划分/区域划分等方式 Partitioner可以是new HashPartitioner(numPartitions) |
P58 |
| rdd2 = rdd1.groupByKey([numPartition]) | 对rdd1中的<K,V>按照key聚合在一起,形成<K,List(V)。参数默认rdd1分区数可指定。若需shuffle,一般换用reduceByKey() | P59-60 |
| rdd2 = rdd1.reduceByKey(func,[numPartition]) | 同groupByKey对相同key的value进行聚合,区别在聚合过程使用func对value融合计算,在shuffle情况下先对rdd每个分区combine再reduce聚合计算,效率比groupByKey高 | P60-61 |
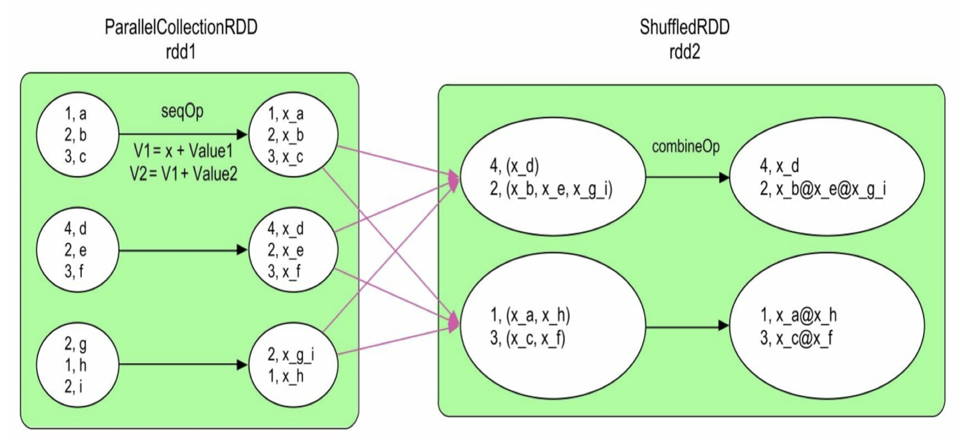
| rdd2 = rdd1.aggregateByKey(zerovalue)(seqOp,combOp,[numPartition]) | 更通用的聚合操作,可在combine和reduce使用不同的操作,同时可设置初始值。首先对rdd每个分区用seqOp作combine再用combOp作reduce聚合计算 | P62-63 |
| rdd3 = rdd1.cogroup(rdd2,[numPartition]) | 将RDD1中的<K,V>和RDD2中的<K,W>按照key聚合在一起,形成<K,List |
P66 |
| rdd3 = rdd1.join(rdd2) | 将RDD1中的<K,V>和RDD2中的<K,W>按照key关联在一起,形成<K,(V,W)>,舍去单独K的元祖 | P68 |
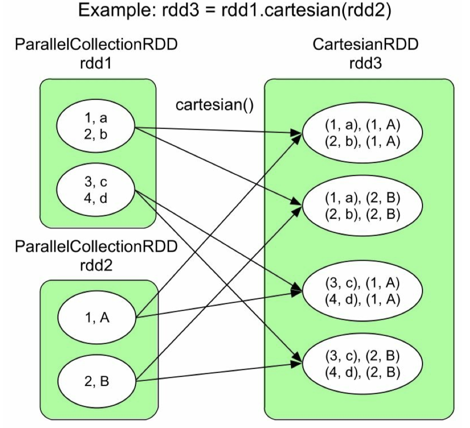
| rdd3 = rdd1.cartesian(rdd2) | 计算两个RDD的笛卡尔积,返回所有可能的配对元祖,注意是多对多的窄依赖 | P70-71 |
| rdd2 = rdd1.sortByKey(true,[numPartitioin]) | 对rdd1中的<K,V>按照Key排序,true为升序false降序 | P71 |
| rdd2 = rdd1.distinct([numPartition]) | 对rdd1中的元素进行去重 | P76 |
| rdd3 = rdd1.union(rdd2) | 将rdd1和rdd2中的元素合并在一起 | P77-78 |
| rdd2 = rdd1.coalesce(numPartition,[true]) | 将rdd的分区个数升高或降低为numPartition,若想要增加分区或者想要减少分区且不希望造成数据倾斜,第二个参数需要设置为true来启动shuffle,或使用repartition | P73-74 |
| rdd2 = rdd1.repartition(numPartition) | 和coalesce(numPartition,true)完全相同 | P74 |
| repartitionAndSortWithinPartitions(partitioner) | 等同于repartition()+sortByKey(),但效率更高 | P74-75 |
| rdd3 = rdd1.intersection(rdd2) | 求出两个RDD的交集,即共同元素组成rdd3 | P75 |
| rdd3 = rdd1.zip(rdd2) | 将rdd1的元素和rdd2元素连接在一起,rdd1中为K,rdd2为V,组成<K,V> | P78-79 |
| rdd2 = rdd1.zipWithIndex() | 对rdd1的数据从0开始递增编号<k,0>、<k,1>…. | P81-82 |
| rdd3 = rdd1.substract/substractByKey(rdd2) | 计算在rdd1中的元素/key而不在rdd2中的元素 | P82-83 |
| rdd2 = rdd1.sortBy(func) | 同sortByKey对元素排序,区别在可实现对value排序 | P84-85 |
| rdd2 = rdd1.glom() | 将rdd1中每个分区的元素合并到List中 | P85 |
常用action()操作
| val res = rdd.count()/ countByKey()/ countByValue() |
count统计rdd中元素个数,返回Long类型 countByKey统计rdd中key出现的次数,返回Map[K,long] countByValue统计每个元素出现次数,返回Map[T,long] |
P86 |
|---|---|---|
| val res = rdd.collect()/ collectAsMap() |
collect将rdd中元素收集到Driver端得到Array[T] AsMap将rdd中<K,V>收集到Driver端得到Map[K,V] |
P88 |
| rdd.foreach(func)/ foreachPartition(func) |
foreach将rdd每个元素按照func处理 foreachPartition将rdd的每个分区的数据按照func处理 |
P88 |
| rdd.reduce(func)/ aggregate(zeroValue)(seqOp,combOp) |
reduce同reduceByKey,对元素按照func聚合计算 aggregate同aggregateByKey,比reduce更一般的聚合 |
P89 |
| rdd.take(num):Array[T] rdd.first():T rdd.takeOrdered(num)/top(num) rdd.max()/min() |
将rdd中前num个元素取出组成数组返回 取出第一个元素,类似take(1) 取出rdd中最小/最大的num个元素,要求元素可以比较 计算出rdd中最大/最小的元素 |
P95 |
| rdd.isEmpty() | 判断rdd是否为空,空返回true | P96 |
| rdd.saveAsTextFile/saveAsOjbectFile/saveAsSequenceFile/saveAsHadoopFile(Path) | 将rdd保存为文本文件/序列化对象文件/sequenceFile文件,文件里存放序列化对象/HadoopHdfs支持的文件 | |
| rdd.lookup(Key):Seq[V] | 找出rdd中包含特定key的value,组成List 实际上等同于filter+map+collect |
P97 |
几个比较难的算子需要分析一下:
flatMap()和Map()容易混淆:
- 对于一维数组来说,map和flatmap没有区别。对于多维数组,例如RDD(List(1,2),List(3,4)…),如果想要每个List中的元素+1,则map算子对每个元素+1返回RDD(List(2,3),List(4,5));而flatmap是先map后flat,故他会先得到map的结果,然后将其平坦化,得到RDD(2,3,4,5)
map()和mapPartition()的区别:
- 例如rdd中某个分区的元素是(1,2,3),rdd.map()就相当于
for{ res = func(arr(i)); output(res);},也就是处理完一个元素,就输出出去;而mapPartition是一次性处理完所有数据,再输出,相当于res = func(arr);output(res);
groupByKey()和reduceByKey()/aggregateByKey()的使用场景:
- groupByKey是把rdd1中的<K,V>按照key聚合在一起,形成<K,List(V)。问题在于groupByKey生成RDD的过程中,如果rdd1没有提前使用partitionBy()根据hash划分,会导致shuffle产生大量中间数据、占用内存大的问题,多数情况会使用reduceByKey()
- reduceByKey为了解决groupByKey的shuffle问题,在shuffle之前,先对每个分区的数据进行一个本地化的combine()聚合操作,之后再进行同样的reduce聚合计算,这样减少了数据传输量和内存用量,效率比groupByKey()高
- aggregateByKey是一个通用的聚合操作,当我们想让reduceByKey的combine()和redece()使用不同的聚合函数,例如combine()的时候用sum(),reduce用max(),reduceByKey就不满足要求了,这时使用aggregateByKey(zeroValue)(seqOp,combOp,[numPartitions]),seqOp是combine()时的聚合函数,combOp是在reduce()阶段用的聚合函数,zeroValue是进行combine聚合计算若需要的初始值。具体使用案例如下,
val resRDD = rdd1.aggregateByKey("x",2)(_+"_"+_ , _+"@"+_),也就是说在combine阶段使用初始值x和下划线对分区内相同key的value进行连接,在reduce后用@连接相同key的元素
cogroup()、join()、cartesian()容易混淆:
- 比如rdd1<K,V>,rdd2<K,W>
- cogroup是把相同key的value聚合在一起,组成<K,(V1,V2,….),(W1,W2,….)>
- join是把相同key的value关联在一起,组成<K,(V1,V2,…,W1,W2,…)>
- cartesian是计算两个rdd的笛卡尔积,两个rdd中分区元素的两两组合。例如rdd1=(分区1,分区2),rdd2=(分区3,分区4),那么cartesian后得到rdd3=(分区1分区3),(分区1分区4),(分区2分区3),(分区2分区4),如下图所示: