本章的核心问题是如何将逻辑处理流程转化为物理执行计划,下面将详细讲解,请读者结合大数据处理框架图进行学习
物理执行计划生成方法:
- Spark采用3个步骤来生成物理执行计划,下面将详细介绍这三个步骤
- 根据action()操作顺序将应用划分为作业(job)
- 注意:spark会按照顺序为每个action()算子生成一个job,这个job的逻辑处理流程是从输入数据到最后action()操作
- 根据shuffle依赖(宽依赖)将job划分为执行阶段(stage)
- 注意:划分stage是从后往前的,遇到窄依赖就纳入并继续往前,遇到宽依赖就停止并划分为一个stage。如下图所示,先从result开始往前,到CoGroupedRDD有一个宽依赖和一个窄依赖,划分开,然后继续对另一个窄依赖回溯,到shuffledRDD宽依赖结束得到stage2。同理向前回溯,得到stage1和0
- 常见的shuffle依赖有:partitionBy,group/reduce/aggregate/..ByKey,coalesce(shuffle=true),repartition,sortBy,distinct等
- 根据分区计算将各个stage划分为计算任务(task)
- 注意:每个stage的最后一个RDD看有多少个分区就生成多少个task。如下图所示,stage0生成3个task,stage1生成4个task,stage3生成3个task
- 根据action()操作顺序将应用划分为作业(job)
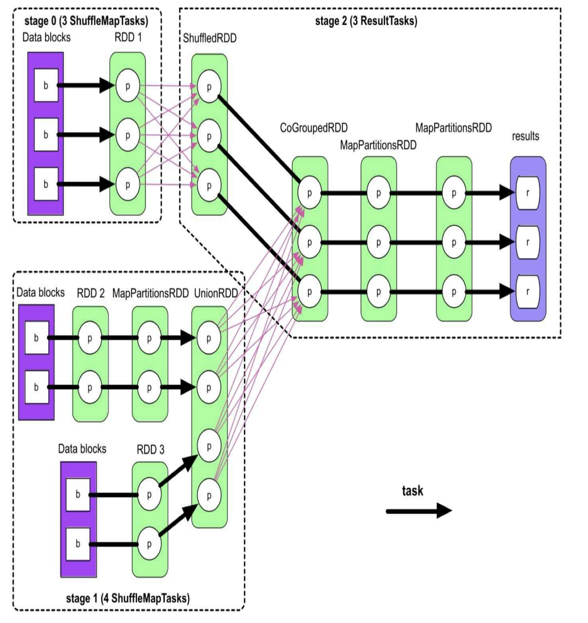
- 总结:Spark可以将一个应用的逻辑处理流程根据action()生成多个job,然后根据job逻辑流程中的宽依赖划分成多个stage,然后根据每个stage最后的RDD分区个数生成多个task,然后同一个阶段的task可以分发到不同的机器上并行执行
一些需要注意的细节
并行细节:
- job的提交顺序看action()的调用顺序
- stage的执行顺序看job内的划分,不依赖上游数据的可以并行,依赖上游stage数据的需要上游执行完才可以执行
- 同一个stage的task可以在不同机器上并行处理
task内部数据存储与计算细节:
- 当上游分区与下游分区内的record是一一对应的关系,采用”流水线”式的计算。例如rdd.map().filter(),内存里一个record进来把map和filter都算完后再读取下一条record。这样就不用在map和filter之间存储中间数据,减少内存使用空间
- 当然例如mapPartition这种需要一次性把数据弄到内存的不能使用“流水线”式的计算

