逻辑处理流程四部分:
- 数据源:从hdfs,hbase甚至内存里的数据结构,流式处理还可以是网络流
- 数据模型:
- MR里面是<K,V>形式的,只能map(K,V)或者reduce(K,list(V)),不灵活。而spark用的是RDD
- RDD是个逻辑概念,不占内存空间(除非缓存)
- RDD中的数据是在内存里的,但是也只是在计算的时候,算完了就消失了,不会像list一样常驻内存
- RDD包含不同分区,每个分区由不同task在不同节点处理
- MR里面是<K,V>形式的,只能map(K,V)或者reduce(K,list(V)),不灵活。而spark用的是RDD
- 数据操作:transformation()和action()
- transformation():对RDD作单向操作产生新的RDD,而不对原来RDD进行修改
- 注:在Spark中RDD因为流水线执行和容错机制,所以RDD被设计成不可变类型
- action():对数据结果进行后处理,产生输出结果,并触发spark提交job真正执行数据处理任务
- transformation():对RDD作单向操作产生新的RDD,而不对原来RDD进行修改
- 计算结果处理:
如何生成逻辑处理流程:
- 由transformation()算子产生RDD
- 如何建立RDD之间的数据依赖关系?
- 新生成的RDD分区个数:由用户指定或直接由父RDD分区个数最大值决定
- RDD分区间的依赖关系:如下图所示,分为宽依赖和窄依赖
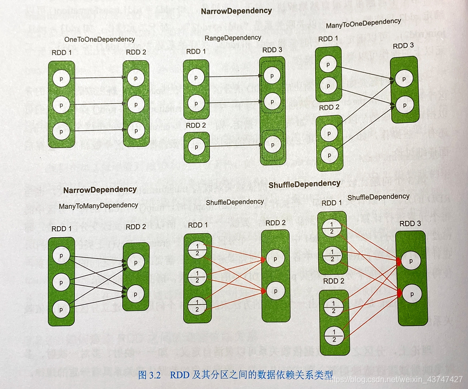
- 窄依赖:新生成的RDD中的每个分区都依赖父RDD的一部分分区,可以根据子RDD依赖于父RDD的分区的全部数据进行判断,包括以下四种依赖
- 一对一依赖:map()、fliter()
- 区域依赖:union()
- 多对一依赖:join()、cogroup()
- 多对多依赖:cartesian()
- 宽依赖:新生成的RDD的分区依赖父RDD的每个分区的一部分,可以根据子RDD依赖于父RDD的分区的部分数据进行判断
- 如图中RDD2只需要RDD1中id为1或2的数据,不需要全部读取
- 如何计算RDD中的数据
- 文中讲解了对输入数据进行map()和mapPartitions()的区别,P49
- map()操作,相当于对每一个元素进行操作后就立即输出结果,来一个处理一个
- mapPartitions()操作,相当于首先加载整个分区中的数据,然后一次性处理完后再输出结果

