在前面章节,我们简单了解了YARN的工作机制,这一章将详细介绍介绍MapReduce是怎么运行
MapReduce YARN的工作机制?
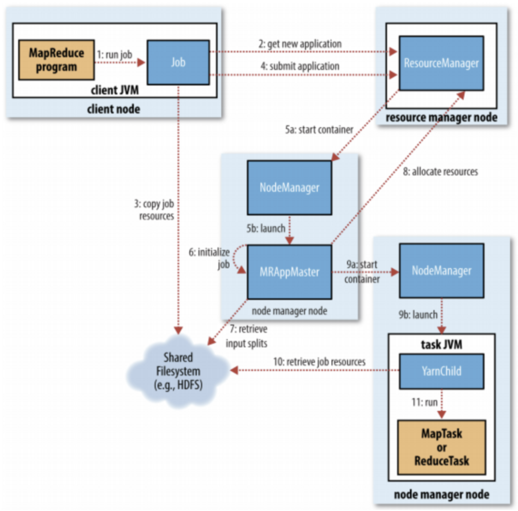
结合上图来学习一下每个步骤:
- 首先是提交作业,直接调用 Job 对象的 submit() 即可,他会创建一个 JobSummiter 实例
- 然后这个 JoSummiter 实例会申请 ResourceManager 给这个作业一个 ID ,ResourceManager 会检查一下
- 然后把需要的资源复制到 HDFS 的文件名是 ID 号的目录下
- 然后 ResourceManager 调用 submitApplication() 方法提交作业
- ResourceManager 分配第一个容器 Container;然后 ResourceManager 在 NodeManager 的管理下,在容器中运行作业的 AppMaster 进程
- AppMaster 对作业进行初始化
- 然后 AppMaster 接收输入数据分片,为每个分片创建一个 Map 任务对象
- 如果是小作业,就直接在自己节点的JVM中运行。大作业的话就向 ResourceManager 申请 Map 任务和 Reduce 任务的容器 Container
- 分配好容器后,AppMaster 就会和这些容器所在节点的 nodemanager 通信来启动这些容器
- 在运行 task 之前,还要接收数据放到自己的本地磁盘上
- 最后运行 Map 任务或者 Reduce 任务
其实在Map和Reduce之间还有一层shuffle
什么叫shuffle?
- 在 Reduce 操作之前,需要保证数据过来都是按照 Key 排序的
- 而把 Map 输出的数据按照 Key 排序并输入给 Reduce 的过程就叫 Shuffle
那么是怎么进行shuffle的呢?
如图所示,绿色的虚线框框就表示的从 Map 输出到 Reduce 输入中间的 Shuffle过程
并且中间两个红色虚线框框分别是 Map 端的 shuffle 和 Reduce 端的 shuffle
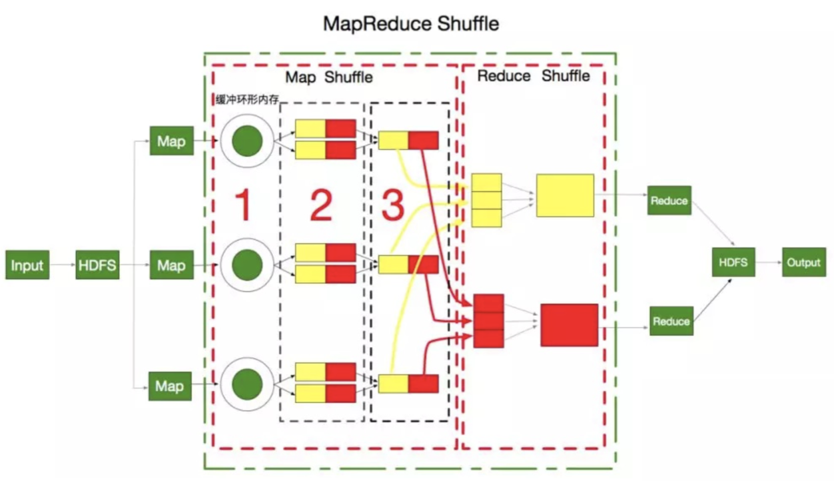
首先是 Map 端的Shuffle
- 每个数据分片由Map任务执行完后,不是直接存到磁盘的,会先存到一个环形缓冲区里
- 当这个环形缓冲区快存不下了,就会溢出到磁盘上,形成一个一个溢出文件,这里有些细节需要
非常注意
- 首先,在往磁盘溢出的过程中,会先按照 Reduce 的个数进行分区,目的是用来指定这个数据要交给哪个 Reducer 处理,就像图中 第2步 有红黄两个 Reducer ,就分两个区,把溢出的文件放到相应的分区里
- 另外,在每个分区中还会根据 Key 进行排序,来一个排一个
- 如果为了优化性能,设置了 Combiner ,也就是提前 Reduce ,也是在分区内进行操作
- 随着溢出文件越来越多,在Map任务结束之前会把所有溢出文件合并成一个已分区和排序的输出文件,如图中的第3步
还有Reduce端的Shuffle
- 每个Map完成时间不同,所以一旦某个Map完成,Reduce都会开始复制Map的输出。每个Reducer都会复制对应分区的数据
- 如果数据比较少,就放到内存缓冲区,如果放不下了就溢出到磁盘上,和Map端一样不断合并和排序,最后合并成一个按Key排序的文件作为Reduce输入

