什么是Spark?
Spark是用来替换MapReduce的,因为它基于内存计算,可以比MapReduce快几十倍几百倍
Spark怎么和Hadoop结合使用?
如下图所示,后面几章将着重介绍Spark Core和Spark SQL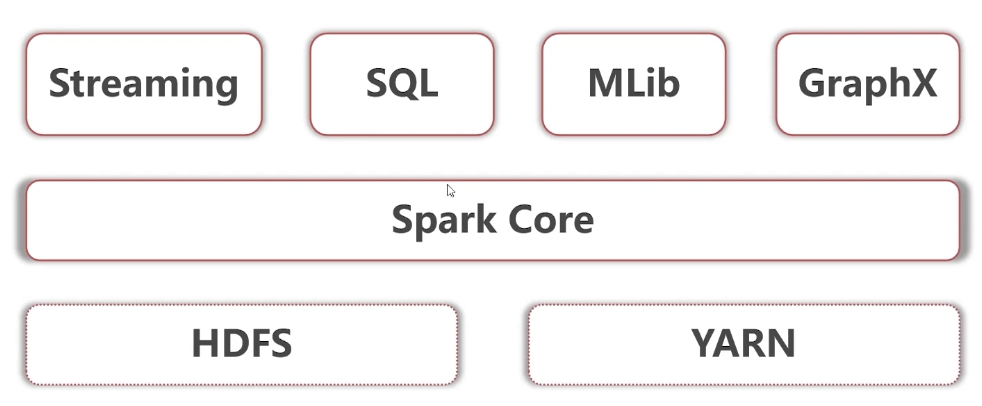
这里简单介绍Spark的工作原理,后面章节会深入分析
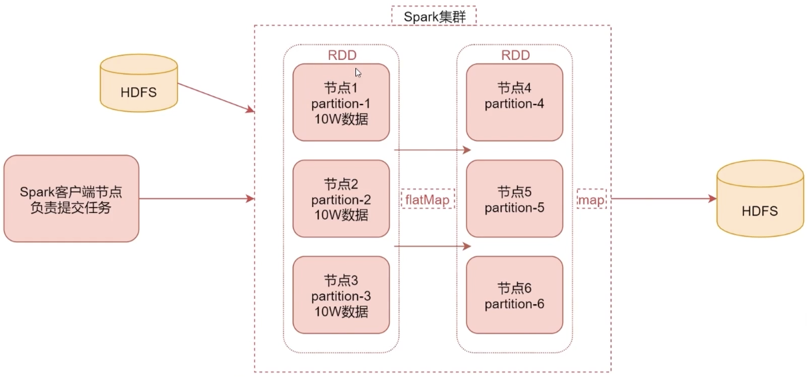
从简化的工作原理图可以看到:
- HDFS的数据加载到内存中转化为RDD,然后假设RDD被分成三份,分别放到三个节点上去,这样可以并行处理
- 中间可以调用多个高阶函数处理后形成新的RDD,然后再通过Map或者其他的一些高阶函数进行处理
- 然后把数据存储出去
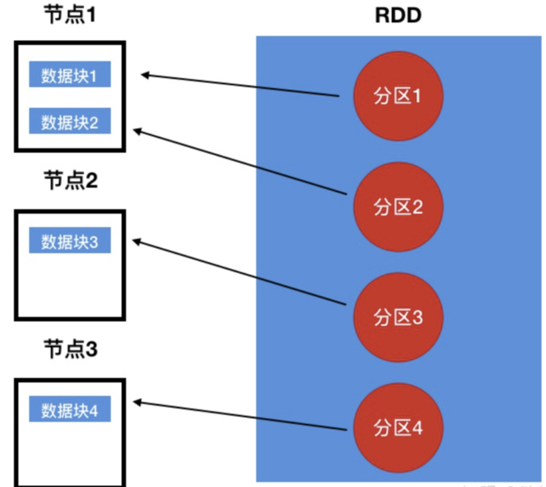
什么是RDD?
- RDD其实是一个抽象概念,弹性分布式数据集。
- RDD这个数据集一般情况是放在内存里的。并且RDD可以分区,每个分区放在集群的不同节点上,从而可以并行操作。另外如果某个节点故障导致那个RDD分区的数据丢了,RDD会自动重新计算这个分区的数据
- 通俗来说,RDD的表现形式类似数据库的视图,是抽象的,如下图所示
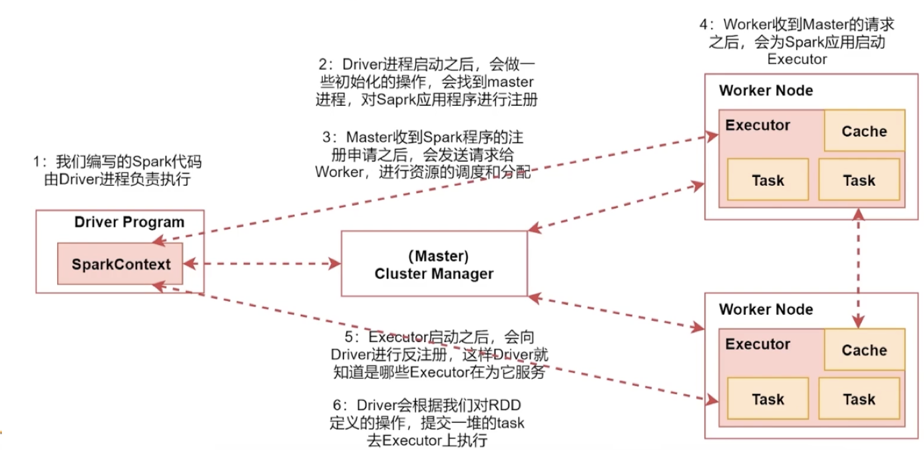
下面简单介绍一下Spark架构原理
[这里以Spark的standalone集群进行分析]
首先要了解几个概念:
- Drive 进程:就是负责执行我们自己编写的 Spark 程序,他所在的节点可以由我们指定,可以是集群上的任意节点
- Master 进程:集群中主节点启动的进程,负责集群资源管理和监控
- Worker 进程:集群中从节点启动的进程,负责启动其他进程( Executor 进程)来执行任务
- Executor 进程:就是 Worker 进程启动的进程
- Task 线程:由 Executor 进程启动的 线程 ,具体运行的就是一些高阶函数、Map操作
- 反注册:Executor 进程告诉 Drive 进程,使得 Drive 进程知道有哪些Executor,方便提交task给他们
接下来学习Spark架构原理,如下图所示:(仅作了解即可,之后深入分析)