在之前章节,我们了解了Spark如何将逻辑处理流程转化为物理执行计划,也学习了如何执行计算任务(task),但是没有详细讨论上下游stage之间和不同节点上的task之间是如何传递数据的,这个数据传递过程实际就是Shuffle机制。
什么是Shuffle机制?
Shuffle机制分为两个阶段,Shuffle Write阶段(map端) 和 Shuffle Read(reduce端)
Write处理上游stage输出数据分区,Read从上游stage获取和组织数据并为后续操作提供数据
第一个问题,如何确定上游stage的输出数据输出到下游的哪个分区?
- 先确定下游的分区数,用户没有指定就是上游stage最后一个RDD的最大分区数
- 如何确定输出到哪个分区呢?根据上游输出的<K,V> 中的key计算partitionID,比如下图分两个分区,那就可以hash(Key)%2得到partitionID,然后直接将record输出到对应下游partitionID的分区中即可
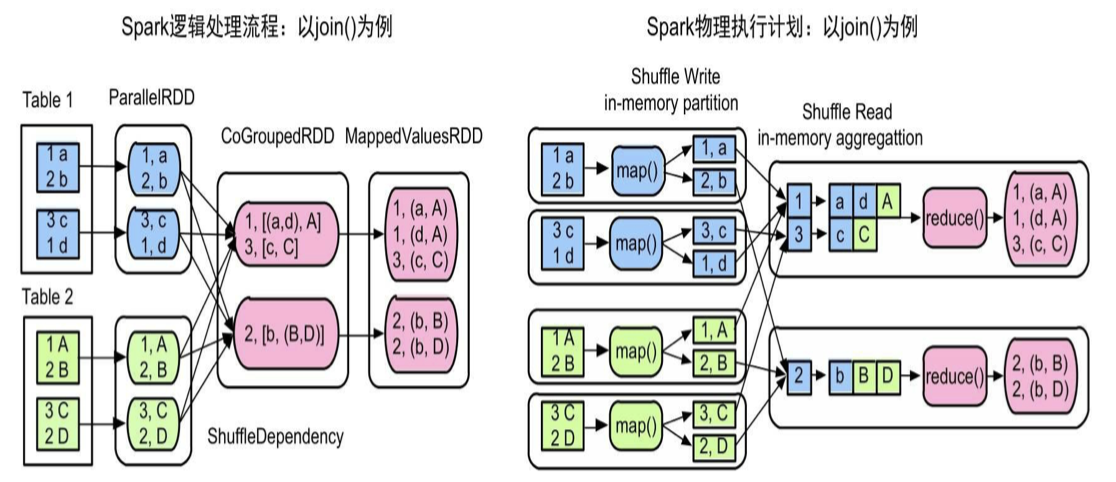
第二个问题,如何获取上游不同task的输出数据并实现聚合操作?
- 首先举个例子,groupByKey()需要把从不同task得到的<K,V>聚合成<K,List(V)>
- 方法是两步聚合,先把从不同task得到的<K,V>放到hashmap中,然后再进行聚合计算,如下图所示
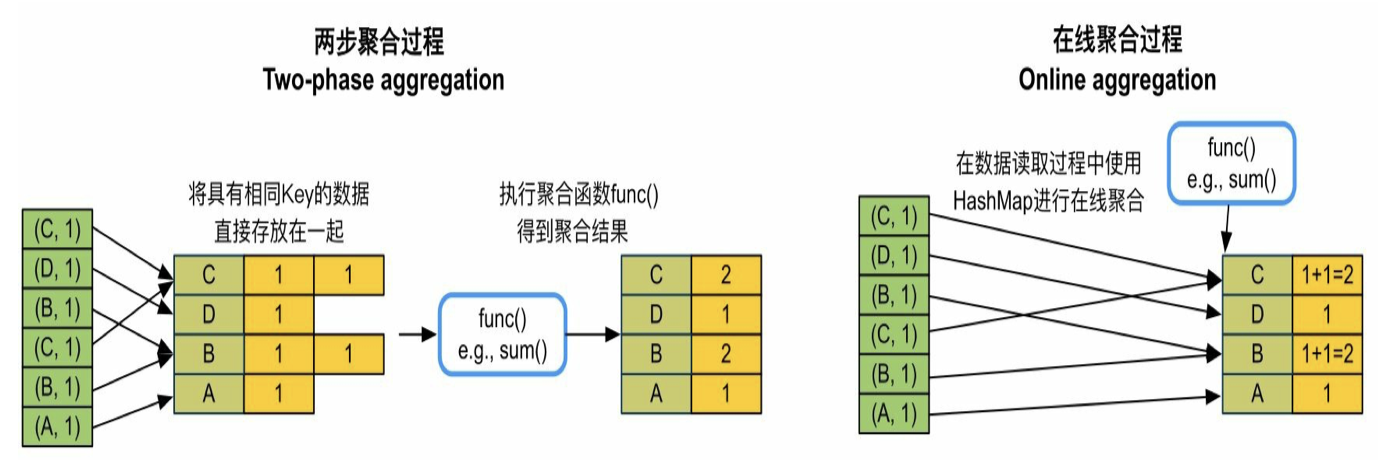
- 优化:所有的record都会被放入hashmap,为了减少空间占用,对于reduceByKey等需要聚合计算的算子采用在线聚合,在每个record加入hashmap同时使用func()更新聚合结果,如上图所示
另外两个Shuffle的重要功能:
combine功能:
我们在前面章节中了解过,为了减少shuffle的数据量,在shuffle之前先进行combine()操作,实际上和shuffleRead一样,利用HashMap进行combine,然后对hashmap的record进行分区计算,然后输出到相应下游分区中
sort功能:
例如sortByKey()需要sort功能,shuffleRead阶段需要把上游数据放在一起进行全局排序。在上游可以先排一下,可以减少read端排序的复杂度,而且上游并行起来肯定比下游一个任务快
内存+磁盘混合存储功能:
试想一下,在shuffle的过程中我们使用hashmap进行聚合计算,当数据量很大的时候内存可能会溢出
这时,采用内存+磁盘混合存储,先在内存(hashmap)中聚合,内存不足就溢出到磁盘,继续处理新的数据,再下一次数据操作之前对磁盘和内存中的数据再次聚合,具体做法后面细说
Shuffle框架设计
下图所示的是一些常用的操作算子的计算需求
Shuffle Write的框架设计
如下图所示,计算顺序为map()输出->数据聚合->sort->分区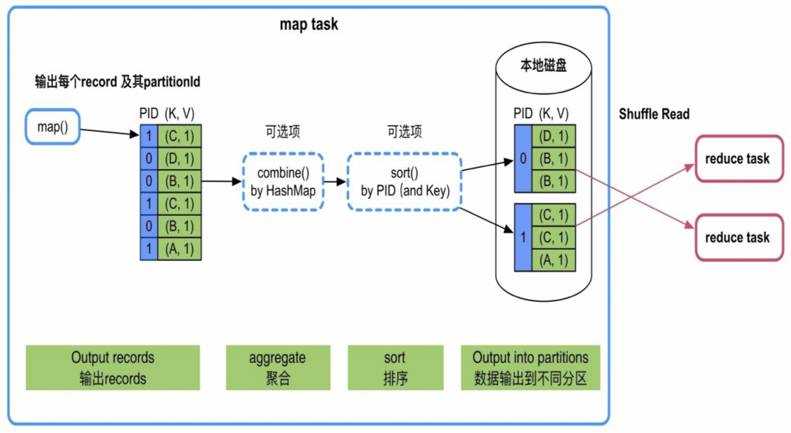
下面详细Spark如何针对不同情况构建Write方式
不需要在map端聚合和排序的情况(join、groupByKey、sortByKey等)
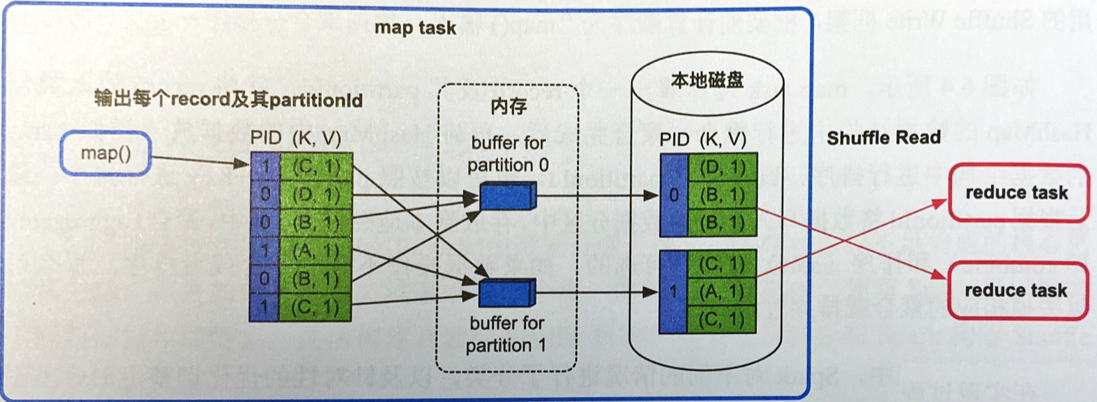
- 只需要实现分区功能,map依次输出record,然后计算partitionID,为每个PID分配一个buffer,spark根据PID把record写到不同的buffer中,buffer满了就写磁盘的分区文件中
- 优缺点:速度快,但是分区越多buffer越多,内存消耗大
不需要map端聚合,但需要排序的情况(目前这样的算子)
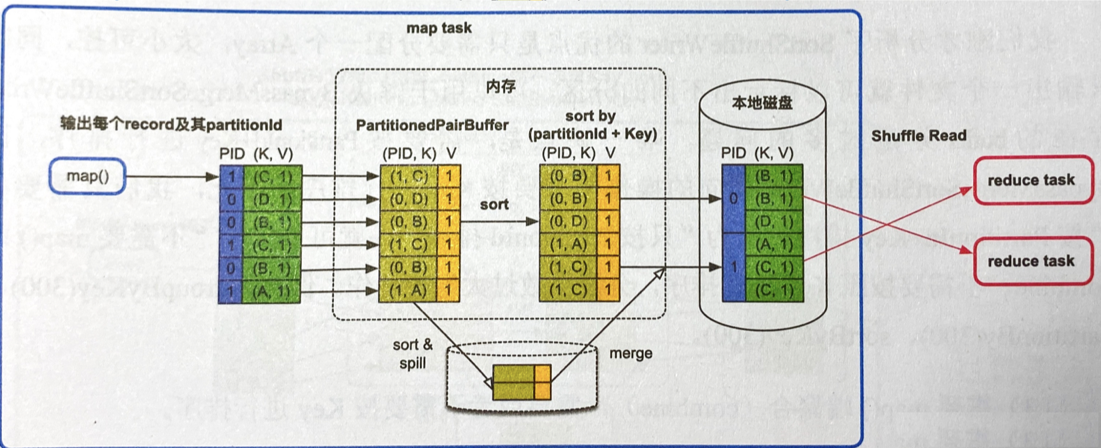
- 建立一个Array(图中PartitionedPairBuffer)来存放map()输出的record,并转化为<(PID,K),V>的record存储,然后按照PID和Key进行排序
- 优缺点:用一个Array结构可大可小可以排序,但排序时间长
需要map端聚合,排序可选的情况(distinct、reduceByKey、aggregateByKey等)
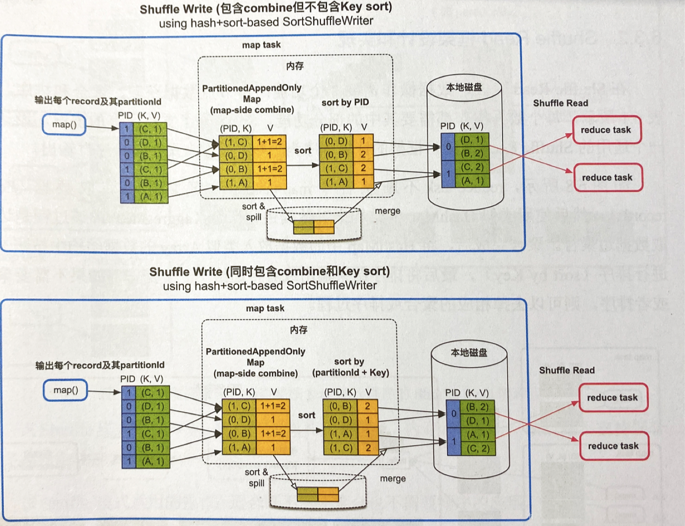
- 先用类似HashMap的数据结构 (PartitionedAppendOnlyMap,实际上就是用Array实现的只能添加或修改的hashmap,因为是Array所以也可进行快排等算法)_ _进行combine在线聚合,来一条record就聚合一条record。如果需要排序(图中下面情况)就按照PID和Key排,不需要就按PID排序,然后输出到磁盘对应的分区文件中
- 优缺点:数据量可大可小,PartitionedAppedOnlyMap很牛逼,又能在线聚合又能排序,最后只输出一个文件省资源
Shuffle Read的框架设计
如下图所示,计算顺序为数据获取->聚合->排序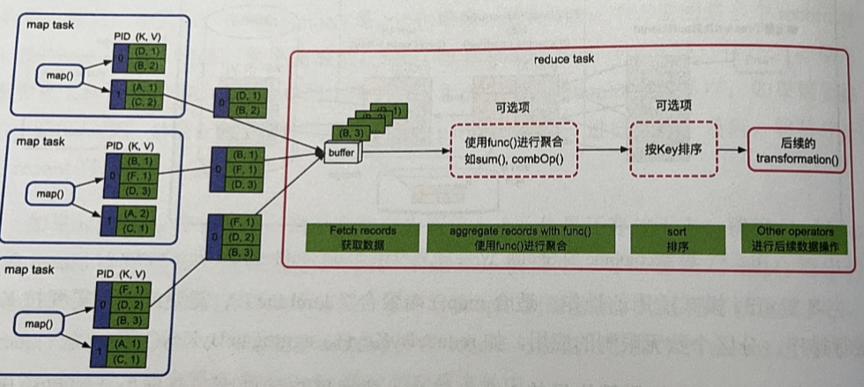
下面详细Spark如何针对不同情况构建Read方式
reduce端不需要聚合和排序的情况(partitionBy)
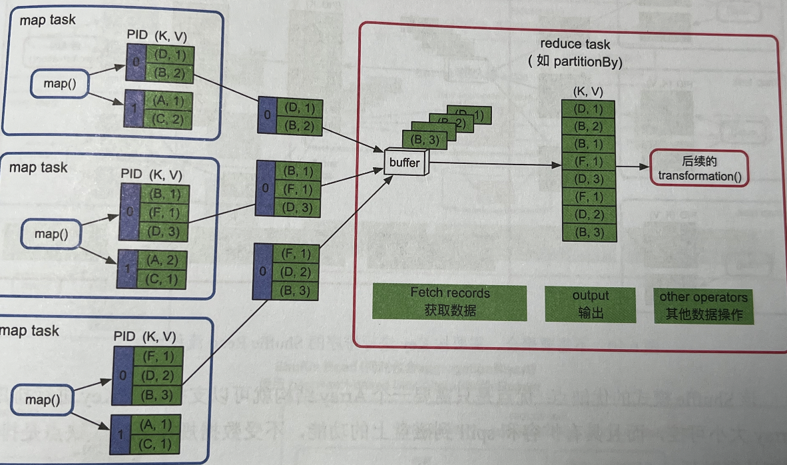
- 开一个buffer,然后收集各个map task输出的record,然后进行后续操作
- 优缺点:内存消耗很小
reduce端不需要聚合,但需要排序的情况(sortByKey、sortBy等)
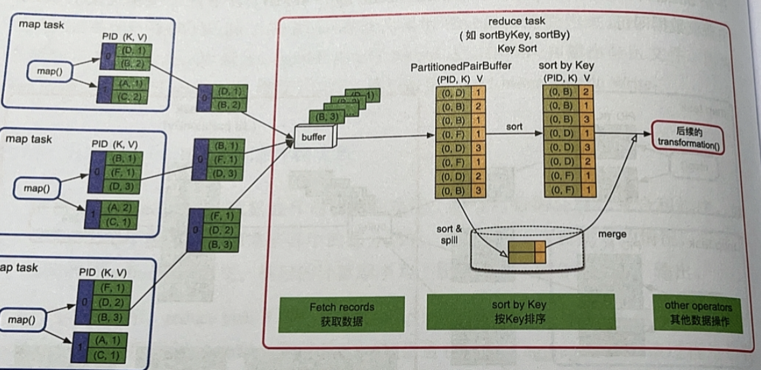
- 获取数据还是通过一个buffer,然后跟write端一样,用PartitionedPairBuffer存数据组成<(PID,K),V>,然后按照Key排序,然后就是后续操作
- 优缺点:数据量可大可小,Array和磁盘一起用,但排序时间长
reduce端需要聚合,排序可选的情况(join、groupByKey、reduceByKey等)
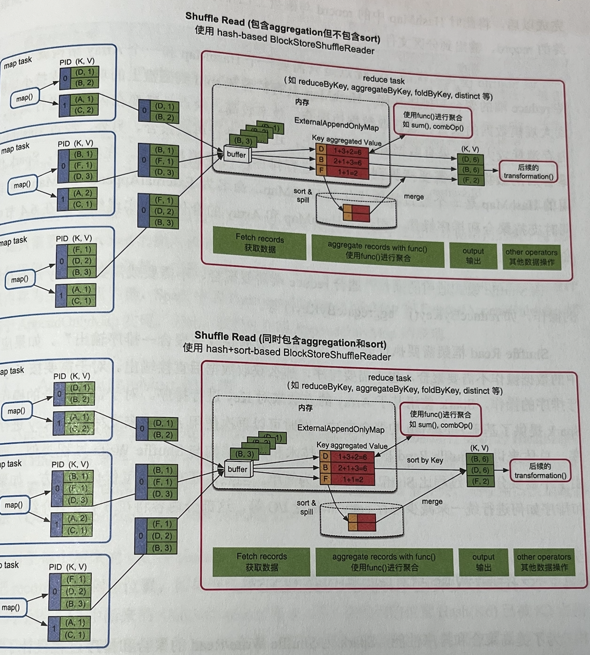
- 用类似HashMap的结构 _ ( ExternalAppendOnlyMap,实际就是在AppendOnlyMap基础上实现溢写磁盘聚合的功能,若要排序则不断维护最后全局排序 ) _ 进行聚合,需要排序就排个序。支持扩容和溢写,最后把磁盘+内存的数据进行聚合,然后进行后续操作
- 优缺点:边获取数据边聚合,效率高,但需要在内存中聚合,溢写磁盘的数据需要再次在Array中聚合,内存消耗大
与MapReduce的Shuffle机制对比
- MR强制按照Key排序,但groupByKey不需要排序,浪费性能,Spark为不同情况设计不同方案
- MR聚合前先把数据全部存好才能进行聚合,Spark采用AppendOnlyMap在线聚合,来一条计算一条,省时省空间
- MR在map端,m个map和n个reduce会产生m*n个临时文件_(《MapReduce工作机制》中有详细讲解)_,Spark输出按照PID排序的数据,只输出一个文件

