数据缓存机制
数据缓存机制是什么?
在执行数据操作算子的过程中,可能会对一些数据多次访问,需要花费大量时间。Spark提供了数据缓存机制,可以把这些数据缓存起来,加快处理速度。
我们来看一个具体的例子:

之前我们学过了job是根据action()算子来提交的,回顾一下之前学过的内容:
代码中的两个foreach的action操作会生成两个job提交,每一个job的逻辑处理流程都是从inputRDD到mappedRDD到foreach。但inputRDD到mappedRDD的过程实际上被计算了两次,可以将mappedRDD缓存起来,这样第二个job就可以直接从mappedRDD开始计算。
哪些数据需要被缓存呢?
一般满足以下两个要求:
- 会被多个job重复使用的数据
- 数据量不是太大。因为cache缓存就是把数据放到内存中,如果数据量太大,会导致内存不足。虽然可以用persist放到磁盘中,但是磁盘I/O代价比较高,速度可能还不如不缓存
怎样使用数据缓存呢?
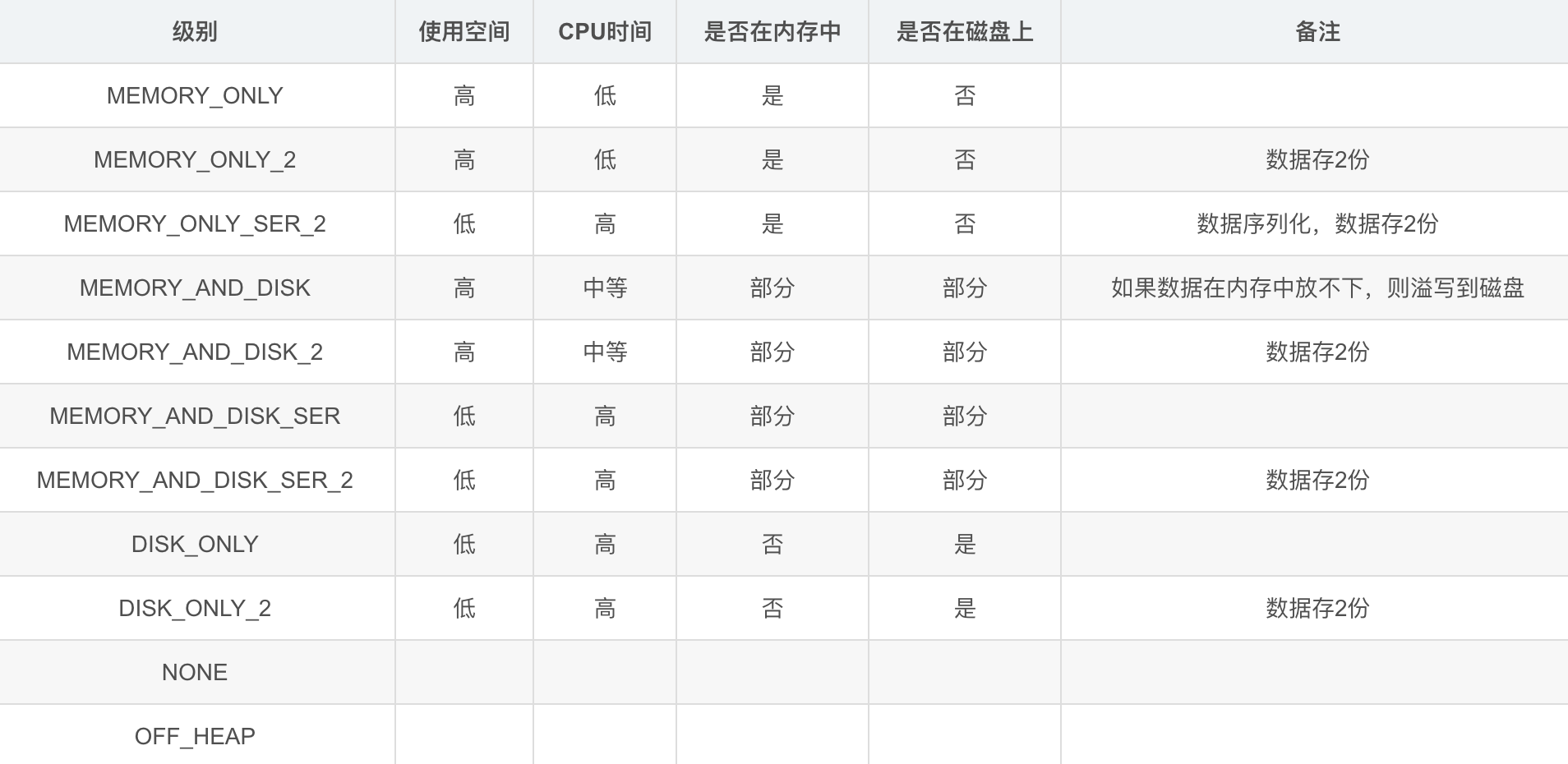
书中这里描述了两个方法,一个是RDD.cache(),一个是RDD.persist(缓存级别)
上面图中就展示了cache的使用案例
- 这里需要注意,cache()操作表示将数据直接写入内存,但同transformation()是lazy操作,不会立即执行,需要等action()提交job后,job执行任务时才会执行
一般情况用cache缓存进内存就可以了,persist可满足其他的缓存需求(存磁盘、序列化、备份),看下图了解即可