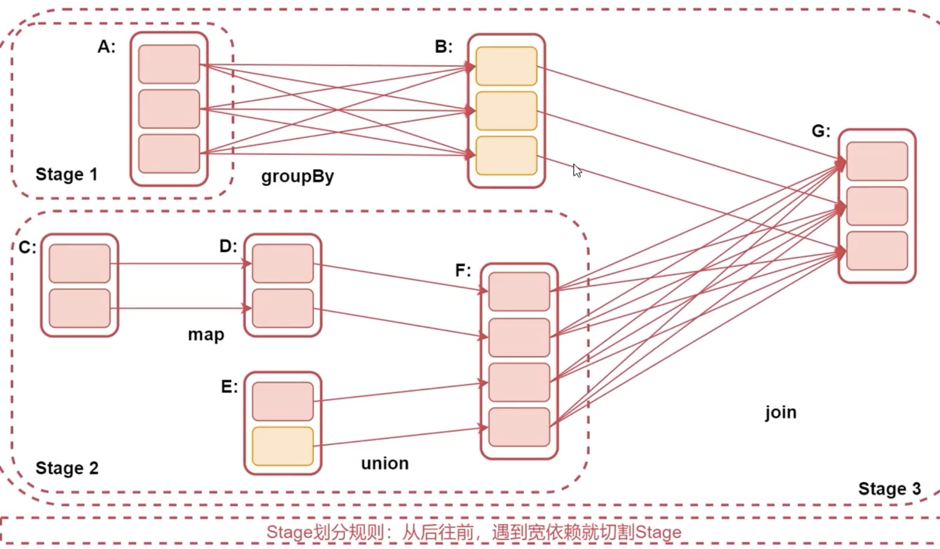
首先要了解宽依赖和窄依赖是什么?
- 窄依赖:每个RDD对应一个父RDD,每个父子RDD是一对一的关系
- 宽依赖:父RDD的partition被多个子RDD使用,父子RDD是错综复杂的关系
- 产生了shuffle操作就是宽依赖
什么是stage?
通过之前的学习,我们了解到Spark job是由action算子触发的,每个action算子触发一个job
每个job会被划分成多个stage,每个stage是由一组并行的Task来完成的
那么Stage是怎么划分的呢?
- stage的划分依据就是看是否产生了shuffle,即是否是宽依赖
- 遇到一个shuffle(宽依赖),就会被划分成前后两个stage,如下图所示
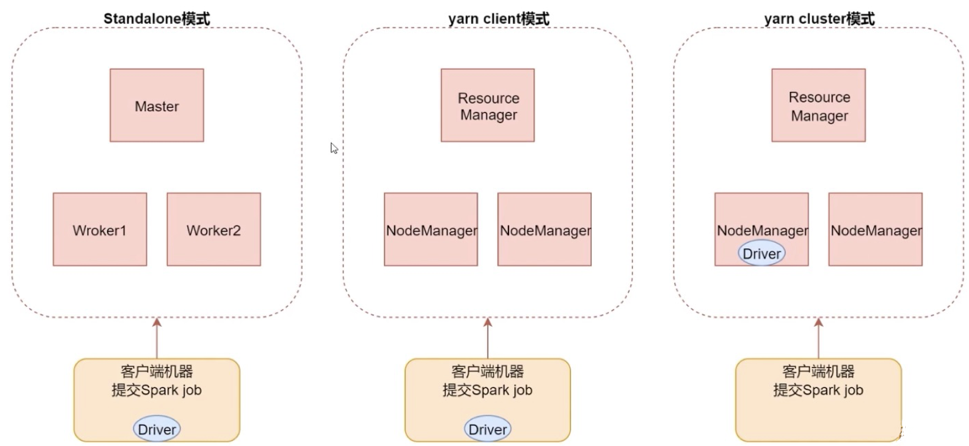
下面我们学习一下Spark job提交的三种模式
- 第一种:Standalone模式
spark-submit --master spark://bigdata01:7077
- 第二种:Yarn client模式(主要用于测试)
spark-submit --master yarn --deploy-mode client
- 第三种:Yarn cluster模式(推荐)
spark-submit --master yarn --deploy-mode cluster
三种模式的架构如下图所示