基本信息
题目:《NAS-BERT: Task-agnostic and Adaptive-size BERT Compression with Neural Architecture Search》
理论方法阐释
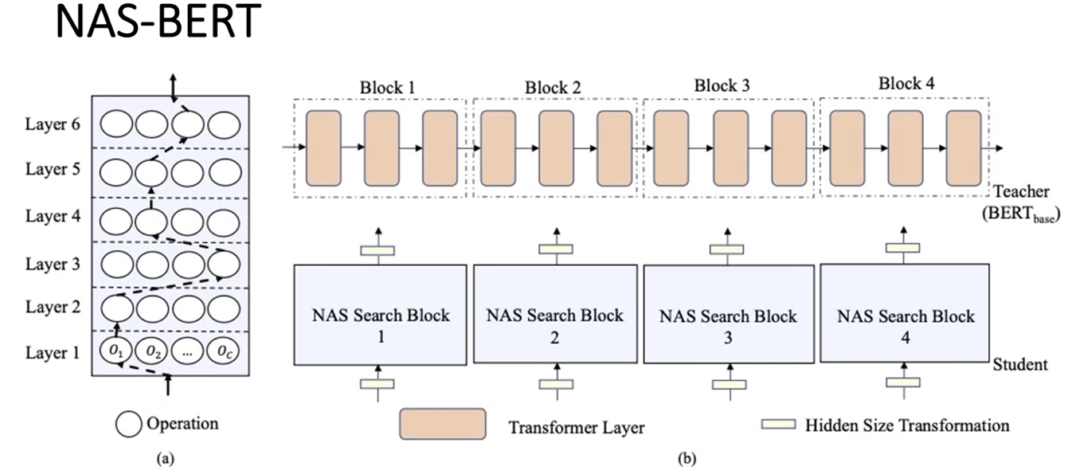
首先给定一个Teacher的模型,在论文中用的是BERT-base。把这个Teacher模型均匀的划分为四个Block,例如前三层作为一个Block,后面以此类推。对于每一个Blcok,我们建立一个NAS Search Block去学习/模仿对应Block的信息或者说学习能力
具体的做法是这样的,一个数据流进来,通过对数据流forward可以得到对应数据流的引表针,那么对每一个Block都可以得到他们的输入输出,每个Block的输入输出代表了他们的函数映射。为了模仿这个函数映射,我们就用这个映射去训练一个NAS Search Block来学习对应的Block的能力,NAS Search Block就是图(a)中所示的框架
NAS Search Block假设有六层,每一层有c个 candidate Operation,通过在每一层选择 candidate Operation构成一条自底向上的路径,可以看到可以有非常多的路径可以选择,通过训练得到一条性能最好的路径得到架构
candidate Operation有以下几种选择
- Multi-head Attention
- Feed-forward Network
- 卷积
- 无Operation
实验方法阐释
- 在实验中使用的Teacher模型,是一个100M的标准的BERT base的模型,训练中也是使用标准的16GB的数据
- 模型使用的是12层的Transformer,hidden size 768
- super-net用的是24层,为什么用24层呢,是因为一个Transformer里有两层,Multi-head Attention和Feed-forward Network
- 为了评估架构的模型效果,对架构进行重新训练。由于重训的代价比较高,论文中采用了5,10,30,60M四种模型的setting
- NAS-BERT-5, NAS-BERT-10, NAS-BERT-30, NAS-BERTE-60
- 在八个GLUE 的benchmark上以及SquAD1.0和SquAD2.0数据上做了性能的评测
实验1
首先在5,10,30,60M四种模型尺寸的setting下和不同训练方式下对比NAS-BERT和BERT的效果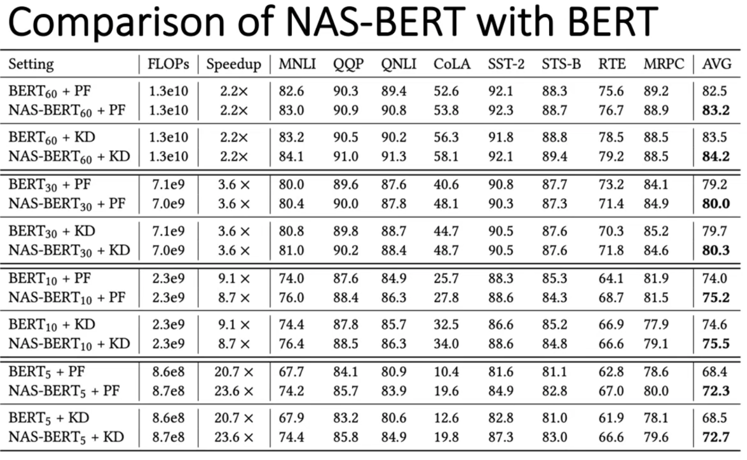
- PF和KD是在两种不同的训练方式去对比模型的效果
- PF表示pre-training和fine-training两个基本的范式
- KD表示用压缩的方式做两阶段的知识蒸馏
- 测试了模型的计算量(FLOPs)、加速比(Speedup)、八个数据集以及八个数据集的平均值
- 可以看到在不同的模型Setting下,NAS-BERT都显著超过BERT模型,并且当模型越小差异值越大
实验2
和之前的模型压缩的工作进行对比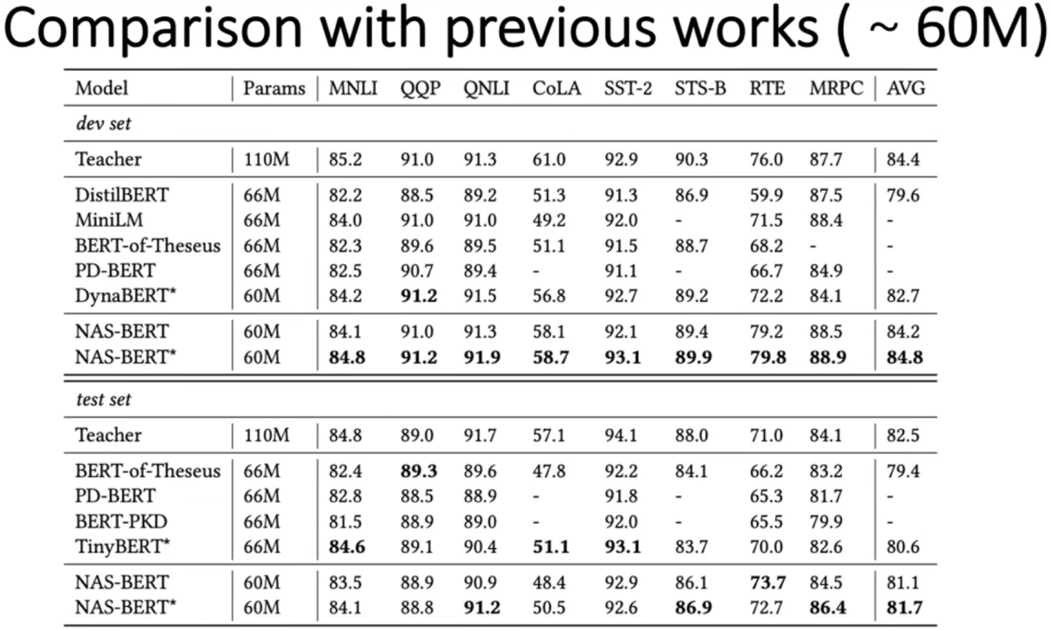
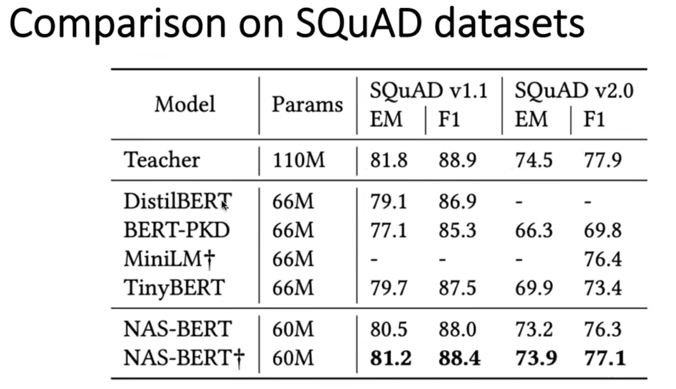
- 在八种数据集上以及SQuAD1.1和2.0数据集上分别在验证集和测试集上进行对比,还加入了数据增广的模型进行对比,如图中带*的模型
- 可以看到不管是在验证集还是测试集上,NAS-BERT都要显著超过之前的方法
实验3
测试如果提出的NAS-BERT不使用progressive shrinking的性能效果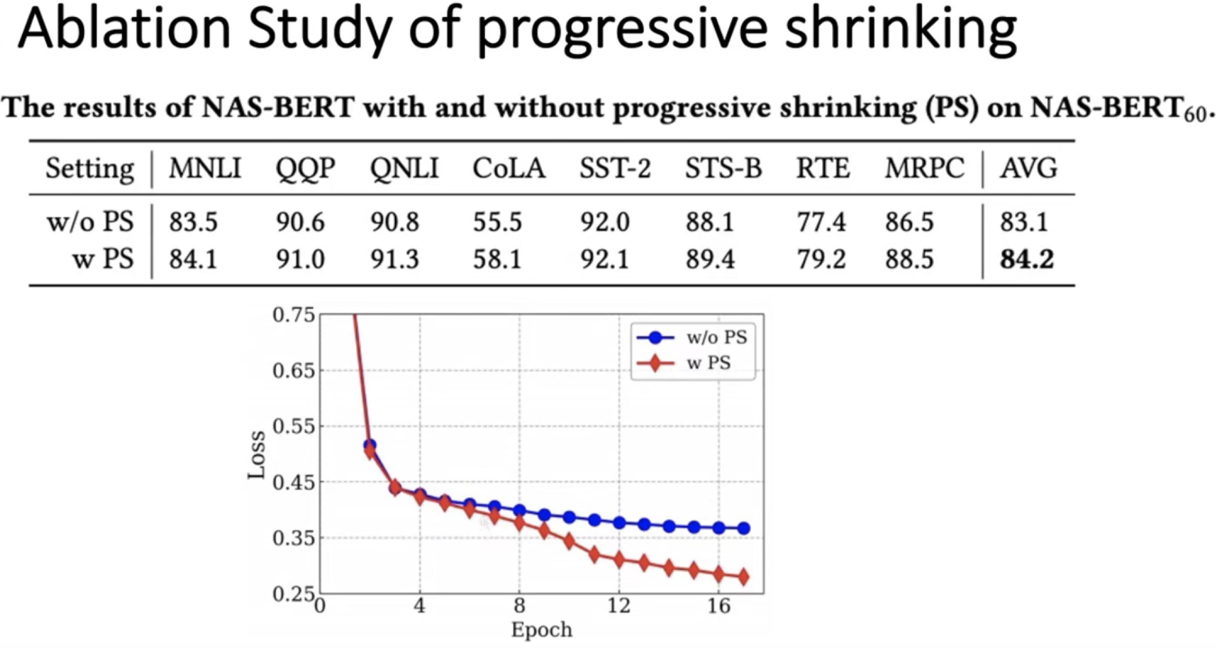
在第4个epoch的时候加入progressive shrinking,即图中红线所示。蓝线是不加入progressive shrinking
可以看到,加入progressive shrinking以后,loss是快速下降的,也就证明super-net的收敛速度是显著加快的
从表格上也可以看出,使用了progressive shrinking是显著超过不使用progressive shrinking的
实验4
测试不同的shrinking方法的性能效果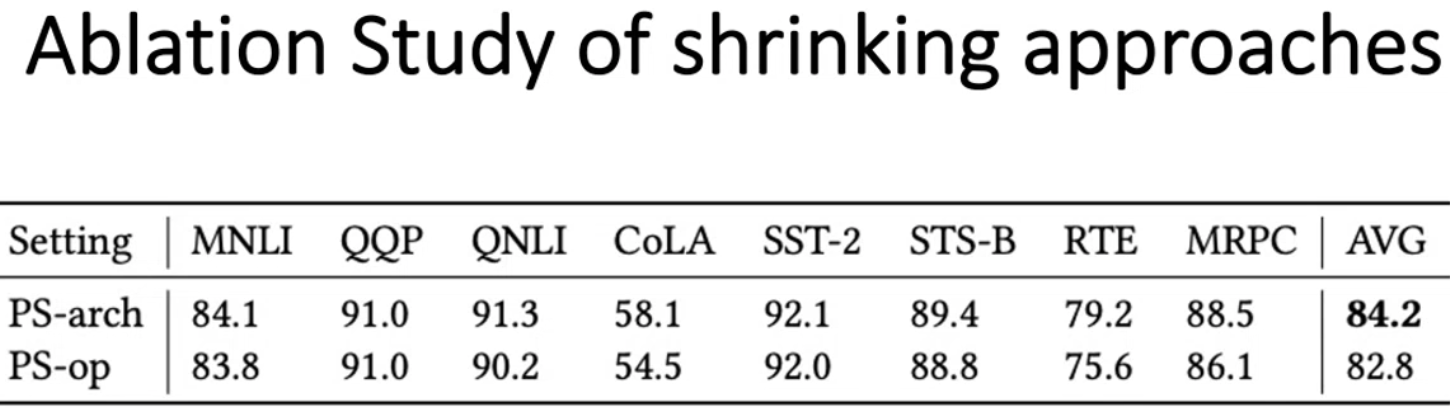
实验5
对比测试在不同的蒸馏setting下的NAS-BERT和BERT的性能效果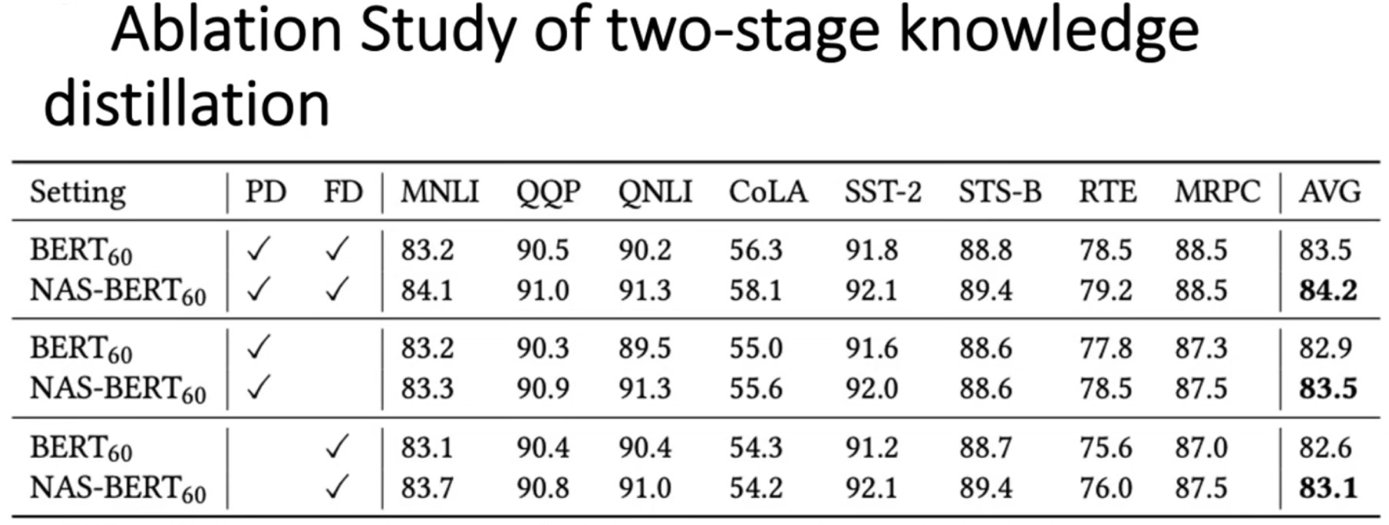
实验分别测试了仅上游使用蒸馏、仅下游使用蒸馏的以及上下游同时使用蒸馏
在八个数据集上NAS-BERT都显著超过BERT模型,证明了NAS-BERT模型并不是只有在两阶段蒸馏的情况下才有效

