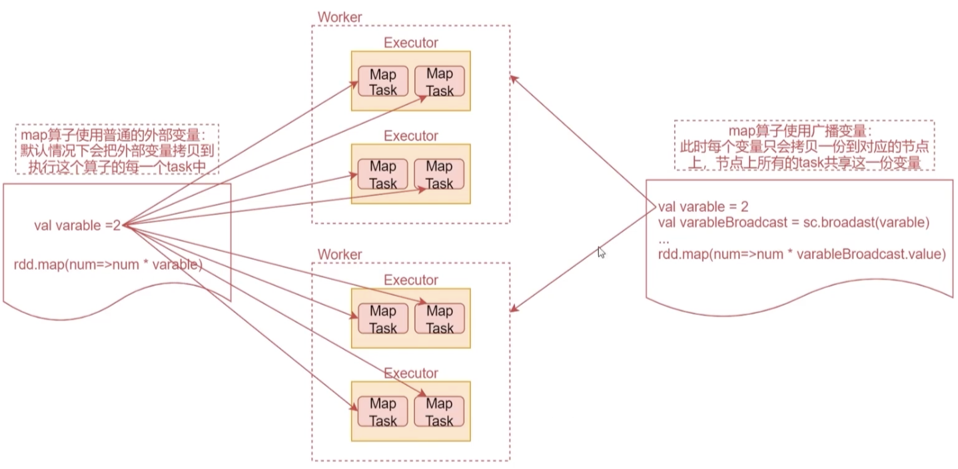
默认情況下,一个算子函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中,此时每个task只能操作自己的那份变量数据
Spark提供了两种共享变量,一种是 Broadcast Variable(广播变量),另一种是 Accumulator(累加变量)
Broadcast Variable(广播变量)
Broadcast Variable(广播变量)会把指定的变量拷贝一份到每个节点上
- 通过调用 SparkContext.broadcast(指定变量) 方法为指定的变量创建 只读 的广播变量,通过 广播变量.value() 方法获取值
- 优点:
- 如下图所示,如果不使用广播变量,当map计算时会把外部变量拷贝到每个task中,当一个节点task很多的时候会消耗很多资源。用广播变量的话,每个节点只拷贝一份,大大提高了性能
Accumulator(累加器)
Accumulator 只能 专用于累加,并且除了Drive进程以外,其他进程都不能读取值
直接看案例就懂了
1 | val sc = SparkSession.builder().getOrCreate().sparkContext |
Cache
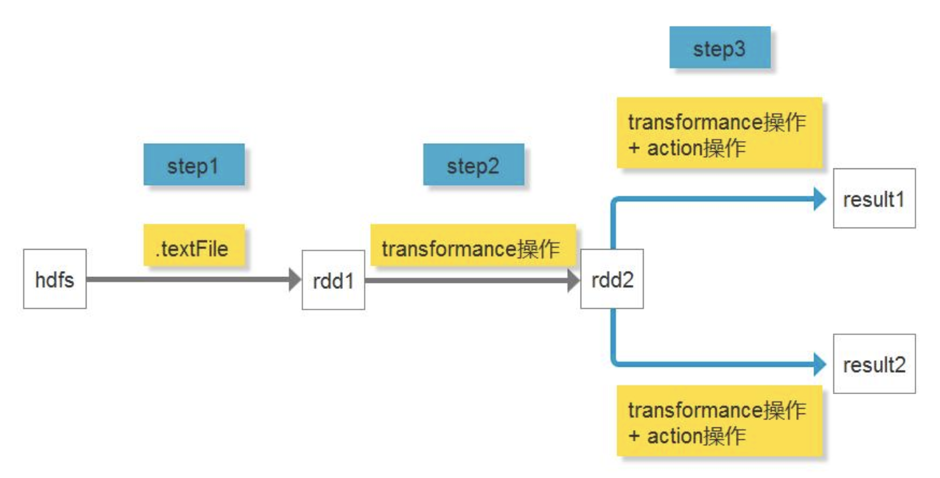
- 在未引入Cache时:
- 如图所示,因transformation算子有lazy特性,在action之前不会执行。所以当计算result1时,会走一遍step1->2->3,当计算result2时,还会走一遍step1->2->3,极大浪费资源。
- 那么现在引入Cache:
- 在RDD2添加Cache后,计算result2时可以直接从Cache中取出计算过的RDD2即可,无需重复计算RDD2
由此可见,在需要重复调用的RDD上非常有必要添加Cache,直接使用RDDname.cache()即可

