如何在IDEA中配置Spark开发环境?
- 首先自行下载scala,并在IDEA中加入scala的SDK,因为spark2.4.3依赖scala2.11,故这里下载scala2.11.11
- 并在pom.xml中添加spark2.4.3的依赖
1
2
3
4
5
6
7<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
</dependencies>
下面介绍Spark的Standalone模式的系统架构
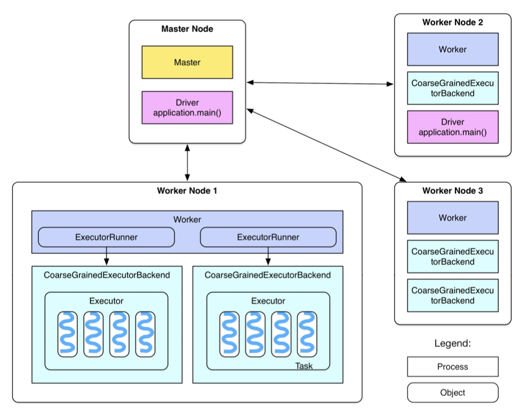
- 上图所示即为Standalone模式架构图,下面将详细介绍
- 首先需要了解几个概念:
- MasterNode:该节点上常驻Master进程,负责管理全部WorkerNode
- WorkerNode:该节点上常驻Worker进程,负责管理执行Spark任务
- Spark作业:就是一个Spark程序,例如WordCount.scala
- Drive进程:就是运行Spark程序中main()函数的进程
- Executor:就是Spark计算资源的一个单位,用这个单位来占用集群资源,然后分配具体的task给Executor。在Standalone模式中,启动Executor实际上是启动图中的CoarseGrainedExecutorBackend的JVM进程
- Task:Driver在运行main()函数时,会把一个作业拆成多个task,以线程方式在Executor执行如map算子、reduce算子。每个Executor具有多少个cpu就可以运行多少个task,如图中八个cpu两个Executor,故每个Executor可以并行运行4个task
- 然后介绍一下流程:
- 启动Spark集群时,Master节点会启动Master进程,Worker节点上启动Worker进程
- 接下来就提交作业给Master节点,Master节点会通知Worker节点启动Executor
- 分配task到Executor上执行,每个Executor可以执行多个task,每个task启动一个线程来执行
- 还有一些细节:
- Worker进程上有一个或多个ExecutorRunner对象,每个对象可以控制一个CoarseGrainedExecutorBackend进程的启动和关闭

