首先了解一下大数据处理框架的四层结构
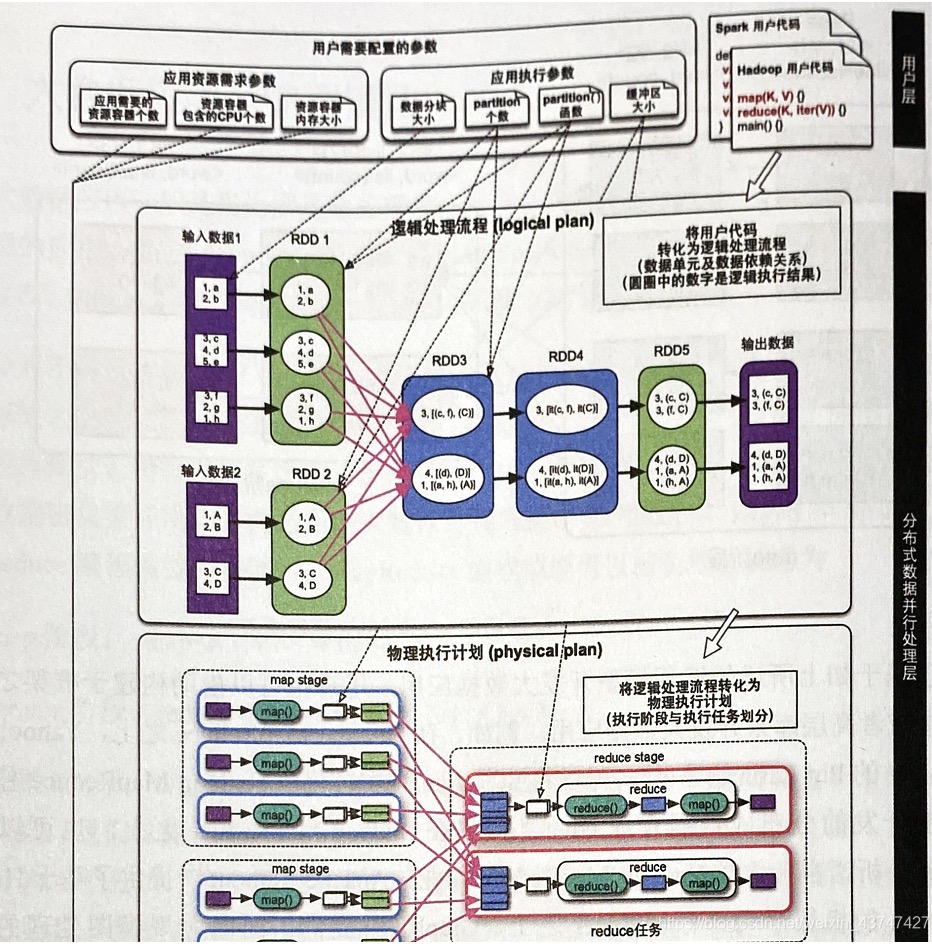
- 上图所示,即大数据处理框架四层结构,下面将逐一介绍
用户层
- 这一层主要是准备输入数据、Spark或Hadoop的用户代码、配置参数
- 输入数据:一般以分块形式存在HDFS或者Hbase或数据库中
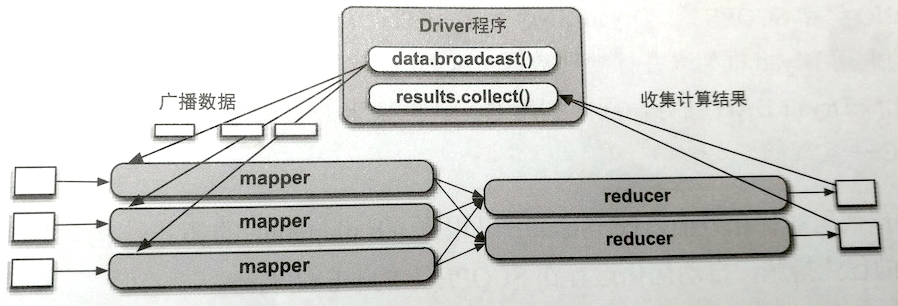
- 用户代码:这里需要了解的是,编写代码后会生成一个Driver程序,将代码提交给集群运行,如下图所示,提交Spark代码后,生成的Driver程序可以广播数据给各个task,并且收集task的运行结果
配置参数:一种是资源需求参数如资源容器数和Cpu大小等,另一种是数据流参数如数据分片大小和分片个数等见四层结构图即可
分布式数据并行处理层
这一层是把用户提交的应用转化为计算任务,然后调用下一层(资源管理与任务调度层)实现并行执行
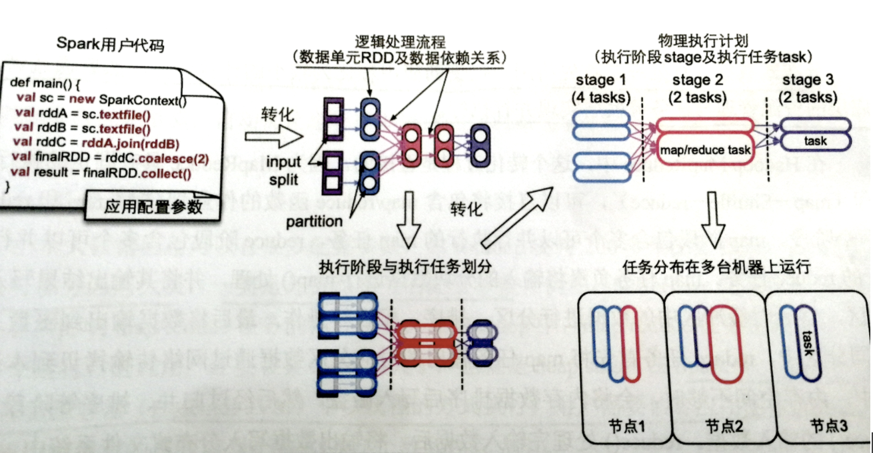
- 转化过程:MapReduce直接就map-shuffle-reduce,但是Spark不一样,如下图所示
- Spark首先要把Spark代码转化为逻辑处理流程,数据处理流程包括数据单元RDD和数据依赖关系,图中每个数据单元RDD里的圆形是RDD的多个数据分片,正方形指的是输入数据分片
- 然后如图对逻辑处理流程进行划分,生成物理执行计划,包含多个stage,每个stage包含多个task,task个数一般就是RDD中数据分片的个数
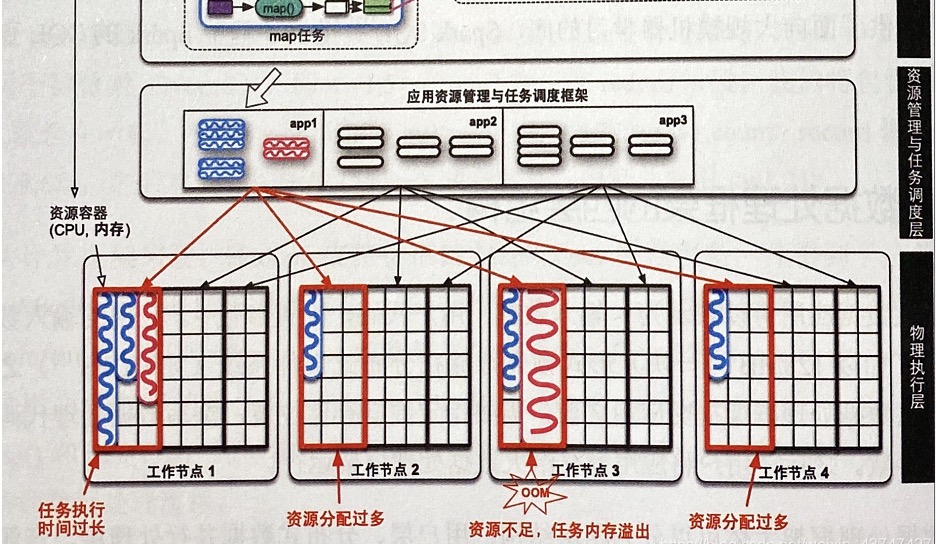
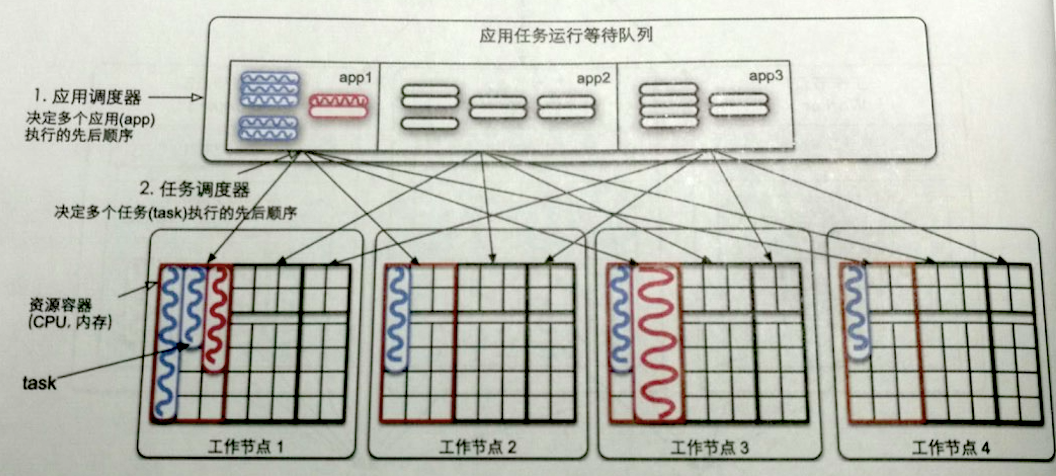
资源管理与任务调度层
- 这一层就是资源管理和任务调度,如下图所示
- 对于资源管理来说,Spark部署模式不同这一层的工作就不同
- 这里仅介绍Spark的Standalone模式,其他模式后面章节会详细介绍
- Standalone模式类似于MapReduce。区别在于MapReduce为每个task将要运行时启动一个JVM进程,而Spark是预先启动资源容器(Executor JVM),然后在task执行时在JVM中启动task线程
- 任务调度有两种调度器:一种是作业调度器:决定多个作业执行顺序;一种是任务调度器,决定多个task执行顺序。下图所示的是先进先出的任务调度器
物理执行层
- 这一层就是负责启动task
- 在Spark中一个作业有很多阶段(stage),每个stage包含很多task,每个task又对应一个JVM的的线程,一个JVM可以同时运行多个task,所以一个JVM的内存空间由多个task共享

