Spark资源参数调优
配置资源前牢记的一些理论
Hadoop/Yarn/OS的守护进程,例如 NameNode、Secondary NameNode、DataNode、JobTracker 和 TaskTracker。在设置—num-executors时,需要保留一个核心来确保守护进程顺利运行
Yarn ApplicationMaster,如果用Yarn运行Spark,需要保留Master需要的资源,大约1024MB和一个Executor
HDFS吞吐量,HDFS在每个Executor约5个task可以实现完整写入吞吐量,所以最好—executor-cores ≤ 5
Executor内存,我们设置的executor.memory后还会加上7%memory的memoryOverhead。比如我们给每个Executor20GB,AM实际上为我们申请了20+20*7%=23GB的内存
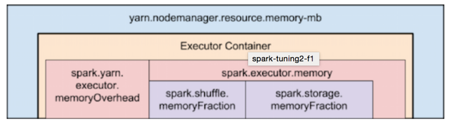
实际案例
案例一
实验室集群配置:三个节点(服务器),每个节点48核和64GB内存
executor-cores:2~4个,大于5会因为HDFS吞吐量导致性能下降
num-executor:每个节点都要为Yarn守护进程保留一个核心 =>每个节点可用的核心数为48-1=47,所以集群内核数 = 47 * 3 = 141,在美团性能优化指南中,每个Executor进程给2~4个cpu核,这里我们给4个的话,那么141/4 = 35个Executor,然后ApplicationMaster又要保留一个Executor,所以—num-executor=35-1=34个,那么平均到每个节点就是34/3=11个Executor
executor-memory:每个节点64GB,每个节点11个Executor,所以每个Executor的内存为64/11=5.8GB,而堆开销是5.8*7%=0.4GB,所以我们设置executor-memory=5.8-0.4=5.4GB
案例二
只用一台服务器,48核和64GB内存
executor-cores:2~4
num-executor:48-1=47,共47个核可用,假设每个executor配置4个核,47/4-1 = 10
executor-memory:64/10=6.4GB,堆开销6.4*7% = 0.4 所以6.4-0.4 = 6GB

